
Running a high-performance, large-scale Kubernetes environment is like speaking a foreign language.
Imagine ordering three Hitachino, Takoyaki, Edamame, and Agedashi without reverting to a smartphone – that’s live translating. When you learn the language, get the order right, and flawlessly request the next three beers without issue, you get to sit back, relax and enjoy the show. Live translation is a great service, but it’s not 100% without bumps, outages, and some unknown plates of food.
I think it’s easy to look at public cloud Kubernetes services and think they’re a “click, wait, done” solution, like live translations or using a GPS for driving instructions. Turn it on and go – you’re at your desired destination, beer in hand, and you know exactly how to get there again…
Recently whilst driving from Kissamos to Chania on the island of Crete, I asked my smartphone for directions. What transpired must be heard.
What happened? The app “read” the language, omega, delta, Cyrillic letter (I’m in Greece, Greek Alphabet, close, but not close enough). I could have guessed some letters as I sped past at 100kph. But knowing the letters still wouldn’t help me know where to exit.
I know you’re thinking, how is this related to K8s? Well, clearly, there’s a difference between reading the letters and speaking the language.
Public cloud Kubernetes services will get you to your destination. However, somewhere along the way, you’ll encounter μετρικός διακομιστής, wonder how critical it is, and then after a few turns you’re certain that you must know what it is and how to operate it.
When we talk to Kubernetes users, we hear constantly that they clicked ‘go’, followed the instructions, and are now wondering why the next three beers are still on the counter and their credit card has been charged.
It’s like my GPS in Greece – they got all the letters correct but missed the exit entirely.
In this blog, I’m going to talk about why we added support for AWS EKS, and how we are building out our cloud-native platform to help DevOps, Platform Operations, and, importantly, Engineering teams.
The case for EKS
No one builds Kubernetes just for the fun of having clusters. They’re built to run apps. Those apps are written by engineers, and eventually, they’ll face the cloud native reality – running apps on Kubernetes means learning how to interact, troubleshoot, and leverage Kubernetes to its fullest.
The last time we asked the community where they run their K8s clusters, 70% of respondents said they were running on AWS leveraging Elastic Kubernetes Service. Amazon’s public cloud is the dominant player in many IaaS and PaaS markets. It is, without a doubt, an innovator and the original. AWS’s pervasiveness has meant that EKS quickly became the foundational backbone to some of the world’s largest cloud native workloads like Snap Inc., HSBC, GoDaddy, and more.
Businesses large and small run on EKS for many reasons. Some because it’s simple to start – nearly any user can leverage the AWS console or the 3rd party open-source CLI eksctl to build a cluster.
Some is thanks to adjacency – EKS is adjacent to every one of AWS’s cloud services, making the decision simple. “We’re already running on EC2 and Dynamo, so why not?”
Another is the 12-factor app. AWS has been delivering services that support cloud-native principles and workloads for years, the AWS Elastic Container Registry, Elastic Container Service, Elastic Load Balancer, and a vast array of storage services. That means many users are already containerized and running in AWS, making EKS the natural evolution.
EKS is great, but it isn’t enough
EKS is a great product. Every cluster built includes out-of-the-box connections to core services Kubernetes externalizes, such as storage, load balancing, and DNS. Nearly any user can, without fail, build a cluster, grab the admin kubeconfig, and follow successfully any number of Kubernetes tutorials.
But building EKS cluster is just the beginning. Businesses now need environments that enable engineers to execute fast without burden.
Engineers require more than a raw cluster with DNS and a load balancer.
- They need application storage, and message bus services like Redis and Kafka.
- The clusters need to be accessible so they can troubleshoot and tune configurations.
- Observability needs to be in place to catch events prior to production.
- At the same time, governance and security policies must be adhered to.
Engineers require a cluster + core applications + policies + monitoring + more.
This means that DevOps and PlatformOps teams must work to create environments by setting up services within each cluster or by leveraging Amazon’s adjacent services. Either way, operations teams need to do more than simply build an EKS cluster. They must take steps to create a complete environment that enables developers to move fast.
The Evolution of the Complete Cluster
Velocity, complexity, availability, and scale are the core factors that lead Platform9 to add support for EKS. We saw that running a high-performance engineering organization at scale requires more than just raw Kubernetes clusters. It demands functional clusters for your engineers in development, ‘like’ clusters in staging, and consistency all the way through to production. All whilst preventing the loss of crucial application manifest configurations, ensuring policies are adhered to, and simultaneously providing seamless access for engineers and operations teams alike.
EKS at scale requires complete environments; the cluster, the core services for engineering, observability, policies for governance, simplicity for operations, increased availability, and reduced risk.
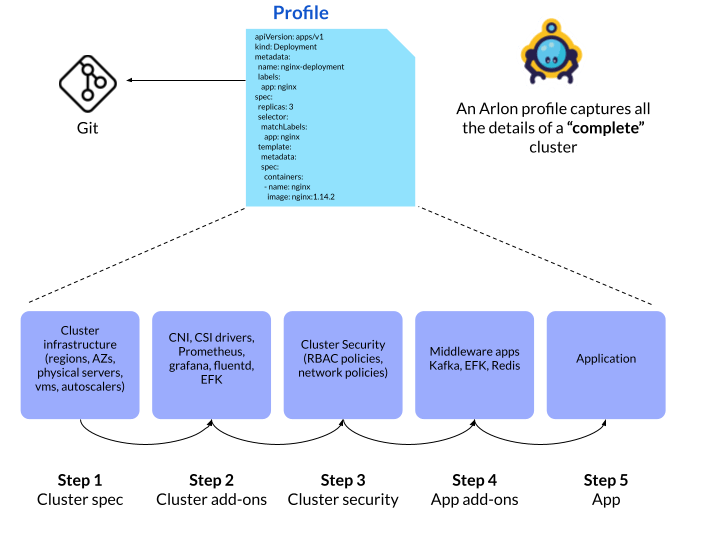
We call this building Complete Clusters. Complete clusters include the base infrastructure (region, instance types, load balancer), plus the cluster configuration (K8s versions, etc.), your policies (RBAC, Network), the core infrastructure applications (CoreDNS, Observability) that your services rely on, and your workloads/core platform applications (Redis, Kafka).
All of this should be able to be delivered fast, based on artifacts that are code, version controlled, and transparent. Complete clusters enable engineers and, at the same time, reduce risk in production, increase availability, and drastically improve disaster recovery.
This is what we mean by complete – an environment that can run your production workloads in an instant and deliver a holistic platform to engineers.
Delivering complete clusters for EKS
Platform9’s EKS support delivers complete clusters. From your code stored in your Git repositories, we automate the process of building a cluster, applying your policies, and deploying your workloads. A single command creates the cluster, connects it to our ArgoCD-as-a-Service, applies your policies, deploys the workload you requested, and, once running, maintains the state of both the cluster and your workloads.
Further, our EKS support creates a unified view and administrative entry point for working with EKS, no matter the Region, and without requiring an AWS IAM Role for every user.
Cluster access goes beyond administrative controls. We extend access to the workloads running within a cluster. Users can leverage Platform9 not just for cluster lifecycle, but also for working with workloads in real-time without the security burden of provisioning every user access to AWS.
Separating AWS access, cluster lifecycle and working with workloads creates an environment where users who are focused on applications can work without limits and operations teams can safely implement access without creating unnecessary policies for access to key infrastructure.
Simply put, we make creating complete clusters a breeze and provisioning secure access for all users scalable. When combined, engineers are empowered to build their own clusters, develop without limits, and not worry about what they’re changing, how the clusters have been configured, or if the container will run in staging and production.
In our next post on this topic, we’ll talk more about unlocking EKS for your developers without sacrificing consistency, reliability, security, or governance. In the meantime, I encourage you to check out our announcement about our latest release, Platform9 version 5.6 and see what this platform offers for private, public, and edge cluster management.



