
Platform9’s OpenStack-as-a-service offers a unique solution by hosting the OpenStack control plane in a SaaS layer, while the VMs and confidential data remain on infrastructure in the customer’s data center. Each Platform9 customer configures OpenStack services specific to their needs, but there are some common patterns in the OpenStack reference architectures. In this blog post we highlight three OpenStack reference architectures that we’ve frequently encountered at our customers.
OpenStack architecture with high availability
In this configuration, the OpenStack services are deployed in a redundant fashion to achieve high availability. This follows the old school approach of running multiple instances of each service, so that the users do not experience any interruption if a service goes down. Please note that the Control plane that provides the service APIs such as nova-api, cinder-api etc, runs in the Platform9 SaaS layer. The servers in the customer’s data center run the workhorse agent for each service e.g. nova-compute or cinder-volume. In this section when we use ‘workhorse service’, it refers to these agents for the respective service.
The control plane monitors the various service APIs as well as the workhorse services. If just the workhorse service goes down on a node, then the monitoring service can bring it back up. If the node itself goes down, then the monitoring service will alert the admin and the node has to be restarted or the workhorse services have to be brought up on another node with available capacity. See this blog for the tools and architecture of Platform9’s 24×7 OpenStack monitoring solution.
As shown in the diagram below, there are three nodes that host the Nova workhorse service and two of those also host the Cinder-Volume workhorse service. Similarly, there are three nodes running the Neutron workhorse service. The Glance workhorse service runs alongside Neutron on one of the nodes. Each of these nodes has a pair of bonded 10Gb NICs. The VMs and Glance Image library are backed by NFS Exports so that should a node go down, the images or VMs can be moved to a different host.
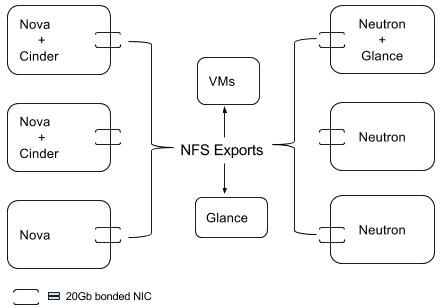
Since there are three instances of Nova and two of Cinder-Volume workhorse services, failure of one instance or of one node will not have a huge impact. The VMs are backed by NFS, so any VMs on the failed node can be recreated on one of the other Nova nodes. Likewise, a new instance of the Cinder-Volume workhorse service can be started on one of the other nodes with available capacity. If any of the Neutron workhorse service instances go down, the other running instances can take over until a new Neutron workhorse service instance is spun up.
There’s only one instance of the Glance workhorse service so it may seem like a single point of failure. However, the images are actually stored on NFS and are not lost if the Glance workhorse service goes down. A new instance of the Glance workhorse service can be spun up quickly on another node and will continue to serve the images from NFS.
In addition, Platform9’s upcoming release v2.2 will support multiple Glance workhorse service instances running in HA configuration against the same NFS store . See this support article for more details to take advantage of this capability in your OpenStack deployment.
OpenStack architecture for high performance workloads
For customers that are running high performance computing workloads or Cloud Native workloads e.g. web applications, the focus is on maximizing compute and network performance. Perhaps, even at the cost of not having a redundant architecture. Such workloads tend to be computational in nature, such as Hadoop jobs, and the required data is sent as part of the workload to the worker node. As such, OpenStack services for storage are not required. See the image below for one possible way to deploy OpenStack for such workloads.
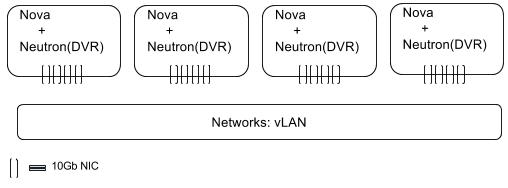
Each node has the Nova and Neutron drivers running Distributed Virtual Routing (DVR). For maximum i/o performance, the nodes have local SSDs that are configured in RAID10. For high networking throughput, each node has four 10Gb NICs that connect to VLAN backed networks.
Each node has 2 processors with 18 cores each, for a total of 36 Cores. To avoid the latency of disk i/o and to load the job data in memory, each server has 1.5TB memory. Given the high-end hardware configuration used in this architecture, it will likely be very expensive to deploy.
The frameworks used to execute these high performance workloads are usually designed to be fault-tolerant to worker node failures e.g. Hadoop. If a worker node fails, there is no loss of data except for the transient computational results. The jobs running on the failed worker nodes will be restarted on other available nodes and provided with the required data from persistent storage.
This architecture trades redundancy to squeeze maximum computing performance and is suitable only for specific types of workloads.
OpenStack architecture with good price-to-performance ratio
This architecture is suitable for Dev/Test workloads and falls in between the previous two in terms of price and performance.

In this architecture, each node runs the Nova driver and one of Glance, Cinder-Volume and Neutron drivers. There aren’t redundant copies of these drivers and any running VMs on a failed node will have to re-created from scratch.
For a good price-to-performance ratio, each node will have 2 budget processors with 256GB of memory. There is a single 1Gb NIC on each node, along with a local HDD that is configured in RAID5. The node running Cinder-Volume drivers uses a local LVM. Networking is configured using VXLAN or GRE.
By default, the overcommitment ratio in OpenStack is 16 Virtual CPUs per physical CPU core and 1.5MB virtual memory for 1MB physical memory on the hypervisor. Given the short-lived and variable nature of Dev/Test workloads, the overcommitment ratio can be increased to squeeze more performance from the hardware. Check this support article for more recommendations on resource overcommitment.
Which other OpenStack reference architectures have you frequently come across? Please share your comments below!


