
In Platform9’s 2.5 release (February 2017), we’ve made some major changes to the way we’re deploying keystone, and we’re on our way to making keystone more scalable and highly available. This post will describe these changes and outline our plans going forward. Please be sure to leave a comment with any questions or suggestions. For background information and a general overview of the OpenStack Keystone service, see:
- OpenStack Keystone landing page.
- Keystone middleware used by OpenStack services to authenticate and help authorized requests.
- Keystone token types, including PKI and Fernet.
Keystone in a Multi-Region Environment
A Platform9 customer’s cloud is made up of multiple collections of OpenStack services, known as regions. Data center resources in separate regions are managed by distinct sets of OpenStack management services (Nova/Glance/Cinder, etc.), all sharing a single set of user, tenant and role settings. Cloud infrastructure might be divided into separate regions for a number of reasons:
- Resources are located in geographically separate data centers. Platform9 will try to locate the controller software near your resources to help minimize latency and improve performance.
- Redundant resources are separated for the purpose of disaster recovery.
- The data center includes distinct virtualization technologies. An administrator with both QEMU/KVM and VMware vSphere resources might manage each as a separate region.
Until our most recent release, Platform9 used a single Keystone server for an entire multi-region setup. All authentication/authorization requests for all regions were routed to a single Keystone service on a single machine with one remote database instance. Although it worked surprisingly well, there were a few obvious (and some not so obvious) flaws in this architecture…
It’s a single-point-of-failure
A keystone service or database failure makes all services in all regions inaccessible. There’s no useful request in any OpenStack service that doesn’t require token authentication and endpoint lookup. If a user can’t fetch a token, or the service can’t validate a token, or a client can’t find an endpoint, the cluster is at a complete standstill.
It doesn’t scale
Although external request volume for our customers is relatively low, it’s pretty easy for a large number of API clients to make a single keystone unresponsive. Many API calls require the cooperation of multiple OpenStack services. For example, to boot a VM in Nova, requests must also be sent to Glance, Cinder, Neutron and possibly other services. Each request along the way requires token validation.
PKIZ tokens help
To reduce the load on keystone, we originally used PKIZ tokens that could be (mostly) validated without Keystone. In this case, Keystone signs a complete authentication context document with a private key and makes the public key available to the services through an API call. Each service can then validate the token and extract the login context using the key. When a valid token is revoked, a service can check a revocation list, available from a keystone API call, to reject the request. With this token scheme, the API calls to Keystone for token validation involve getting the public key and revocation lists. The frequency of these calls is small, so the validation load on Keystone is reduced.
PKIZ tokens come with their own problems
Using PKIZ tokens reduces the token-validation load on keystone, but there are a number of serious problems with them…
It’s difficult to query the Keystone token database. Our token lifetime is 24 hours. When there are a large number of API clients generating new tokens, the token table in Keystone can become very large, even with a cron job periodically pruning expired tokens. In this case, it becomes a major task for Keystone and the database to perform queries against the tokens table. Adding indices to the database improved this.
PKIZ tokens are infeasible for a large number of regions. The token itself must carry an encoded version of the entire login context, including the full service catalog, which contains endpoints for every service in every region. We have customers with up to 10 regions, for whom even the compressed PKIZ token is upwards of 32kB. This string is carried for each request in an http header, and by default, most web servers limit header lines in an http request to 4kB. We were able to limp past this problem by configuring Apache and Nginx, and all the OpenStack service configurations (e.g. nova.conf’s max_header_line) to handle huge headers. We were able to reduce this problem a bit by using the keystone v3 nocatalog option in the API, but we can’t control how all clients fetch tokens, and a few OpenStack services (e.g. heat) can’t cope with login contexts that don’t include the service catalog.
PKIZ tokens are deprecated as of the ‘O’ release. Support for PKI tokens is being deprecated in the Ocata release, and will most likely be removed a few releases later.
Keystone in Platform9 version 2.5
In our next major release, we’re introducing a number of changes that will improve availability and scalability, and will make it easier to move forward into a truly highly available Keystone infrastructure. This starts with replacing PKIZ tokens with the new Fernet token infrastructure.
Fernet Tokens
In Keystone, a Fernet token is a new type of bearer token introduced in Kilo. Like UUID tokens, fernet tokens must be validated with a keystone API call, however because they contain enough information to identify a user context, they don’t need to be persisted in the Keystone database. For a complete description of Fernet tokens, see Fernet – Frequently Asked Questions. Here are a few highlights:
- When a user requests a Fernet token, Keystone generates a small json document and encrypts it with a symmetric AES key. The document contains the user’s name, project, expiration date and a few other pieces of data.
- The token is not persisted in the database, so any Keystone can validate it immediately so long as it has the same signing keys. Other token backends that rely on the database for token validation can run into problems with replication delay in a clustered database.
- Fernet tokens can be generated very quickly.
- When a Fernet token is validated, the full login context (including roles, service catalog) is returned as part of the validation response.
- Since Fernet tokens are small, the problems with http header limits go away.
Fernet tokens solve most of the problems with PKIZ tokens, but for each request to an OpenStack services, a Fernet token must be validated with Keystone. We’ve made some changes to the authentication infrastructure to address this significant increase on the load in Keystone.
Spreading the Load
To handle the new validation load we’re adopting a new Keystone infrastructure for Platform9 2.5. Changes include:
- Running a dedicated Keystone every region. Services within a region are configured to validate tokens and perform other keystone operations on the region-specific Keystone. These Keystones all share a database, and maintain copies of the same set of rotating Fernet signing keys.
- Running memcached in every region and configuring all services to try the cache, first, before asking Keystone to validate a token.
The following shows a three region setup with Region1 acting as the the identity endpoint. External client authentication and identity administration requests are all sent to the Keystone service in Region1, but token validation, and other Keystone requests by OpenStack services are handled within the individual regions, with the help of Memcached.
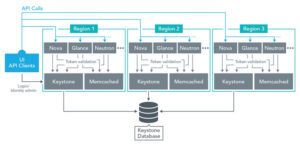
Depending on the number of regions, this configuration can reduce the load on the ‘master’ (Region1 in the drawing above) considerably. Although we haven’t collected data on request/response times, we measured load data on the regions with and without the Keystone token validation service. Our most heavily used region hosts our integration test clusters, and has 11 compute hosts and about 200 VMs at any given time, with a large amount of API requests and VM deletion/creation. Average memory usage on this region’s controller was reduced by about half, and load average stayed about the same, even with the addition Keystone and memcached services.
Next Steps
To turn this into a truly highly available Keystone infrastructure, there are still a few more steps needed:
- Use a combination of virtual IPs and haproxy services to make all the keystones available from the UI/API. With the configuration above, if the the Region1 keystone is down, it’s not possible to fetch a token or administer the identity service — at least not through the publicly available endpoints.
- Use a MySQL Cluster or other highly available relational database system for Keystone.
Look for more posts as we continue to evolve our infrastructure!



