Storage in Kubernetes can really frustrate customers and newcomers to the blossoming cloud-native universe. In countless customer experiences – I can honestly say that majority of customer questions and issues around Kubernetes storage are often rather elementary, and roughly half of them are somehow related to persistent storage models.
These basic questions could easily be answered – if only there was a:
- Shared conceptual model for reasoning about Kubernetes storage paradigms in a Production data center
- Simple, private sandbox where experiments could be run in a reproducible way on the Kubernetes storage API.
In this 2-part article, I’d like to first introduce you to the key concepts and components in the Kubernetes storage architecture, to build a conceptual storage model which is technology agnostic. Then, we’ll turn to see how we can observe the inner-workings of Kubernetes storage and tweak those in a sandbox environment, using minikube.
We’ve published a more recent post about “Storage Considerations as you Migrate to Containers“
Part 1: Kubernetes Storage Deep-Dive
The Economics of Heterogeneous, Dynamic Storage
First, let’s review why there’s no out-of-the-box storage model in Kubernetes. I believe that once you’ve looked at it a bit deeper, you’ll likely agree that the need for distributed storage in any cloud environment (Kubernetes or otherwise) is deceptively complex.
In conceptualizing your storage model – you’ll need a firm understanding of how basic Kubernetes components interact, in a storage-agnostic manner, detached from vendor-specific buzzwords, ansible scripts, or RAID jargon. And for a data center with 100s of applications, “picking one that just works”, is almost never an option. Consider the following table of storage requirements for different workloads:
| Workload | Needs Durability | Needs to be fast | Avg size per container | Dedicated disk? |
| AI Workloads with model or training caches | No | No | 1 to 100GB | No |
| Postgres workloads with millions of rows | Yes | Yes | 1G to 5TB | Yes |
| HDFS datanode backend folders | No | Yes | 10TB | Yes |
| Cold storage | Yes | No | Infinite (assume that over time the amount of storage increases indefinitely) | No |
Now, let’s take into account the fact that a single storage array with 100s of Terabytes can be tens of thousands of dollars. The cost of using the Postgres solution for your cloud storage volumes could easily waste hundreds of thousands of dollars at data center scale. Therefore, it is critically important to estimate what your storage needs are based on your applications workload type.
Rarely will an enterprise be able to survive with only a single type of default storage volume. As Kubernetes matures – developers increasingly expect it to also be able to support transactional workloads like postgreSQL, backups, recycling, and high-performance workloads (for example, in the AI arena).
Although we won’t solve this problem today for you, we will put you in a position where you can begin to effectively model your storage policies and experiment with emerging storage APIs before provisioning a full-blown production cluster.
Dynamic Provisioning in Kubernetes, and How it’s Different
In these articles, we’ll go through the internals of the two rapidly evolving Kubernetes storage paradigms: Dynamic Storage and CSI, in a manner which can be done in any cluster, including minikube, with no fancy configuration needed to get started. We’ll dive deep into the internals of provisioning and provide you with a mental framework for reasoning about the pieces of the ever-evolving primitives in the Kubernetes storage ecosystem.
*Note: It is assumed that the reader of this article is aware of the basic usage of PVC’s and PV’s in a Kubernetes cluster. If not, check out the comprehensive documentation in the upstream Kubernetes community, and then come re-join us for a deeper dive.
Dynamic provisioning, in the most generic sense, is a feature of many cluster solutions (for example, Mesos has had a PersistentVolume offering for quite some time, which reserves persistent, reclaimable, local storage for processes). Every “cloud” must provide some kind of API-driven storage model. But dynamic provisioning in Kubernetes stands out – because of its highly pluggable (PVCs, CSI) and declarative (i.e. PVCs alongside Dynamic Provisioning) nature. These allow you to build your own semantics for different types of storage solutions.
Dynamic Provisioning for Kubernetes storage is implemented by most cloud providers with a simple cloud attached disk type as the default. If you’ve used Kubernetes provided by any of the public clouds, chances are you’ve experienced creating Persistent Volume Claims (PVC) which magically got fulfilled by the underlying, default persistent volume storage.
For many small apps, a slow persistent volume that is automatically selected by your cloud provider is enough. However, for heterogeneous workloads (as shown in the table above), being able to pick between different storage models, and being able to implement policies, or better yet “operators” around persistent volume claim fulfillment, becomes increasingly important.
This is where StorageClasses for dynamic provisioning come in.
Learn more about storage with – Compare Top Kubernetes Storage Solutions: OpenEBS, Portworx, Rook, & Gluster
StorageClasses: Commoditizing Binding, Retention, and Provisioning Policies
StorageClasses are a prerequisite for dynamic provisioning, and there are several knobs in the StorageClass API definition that allow you to communicate preferred storage semantics in a uniform manner to a Kubernetes cluster.
Roughly, you should look at storage classes in the following light:
- StorageClasses are an interface for defining storage requirements of a pod – not an implementation.
- StorageClasses are less descriptive then explicitly declaring volume types.
- StorageClasses are declarative, PersistentVolumes are imperative.
- PersistentVolumeClaims can be fulfilled without a StorageClass.
- StorageClasses are useless without a provisioner which understands them.
- Provisioners can be CSI-based, or in-tree volumes.
- StorageClasses and dynamic storage enable commoditization of storage for many apps, thus, for extremely high performance storage tuning or one-off jobs, you often won’t need a storage class or dynamic storage – at all.
Two knobs which are particularly important to think about in any deployment are the binding and retention modes. We’ll cover these, below.
The Dynamic Storage Lifecycle in Kubernetes
Before we dive into the details, since dynamic storage is often confused with the concept of persistent volume claims, let’s briefly lay down some bread crumbs around where StorageClasses fit into the dynamic storage scheme:
- A pod is created which references a PersistentVolumeClaim (PVC) by the user.
- A PVC is created by the user, and is unbound.
- If the binding mode of that claim is to wait for the first consumer, nothing is done.
- Otherwise, the StorageClass of the claim is checked by the Kubernetes volume controller. If the StorageClass is known by kube, it is used to make a volume, and this is done by a controller running somewhere (typically in the cluster).
- There is now a PersistentVolume, which is bound to (2).
- The pod created is now scheduled to run on a node, and the kubelet on that node mounts the volume when the container is started.
Ok, so now you understand how the magic of StorageClasses enables dynamic provisioning. Automated storage solutions that are this easy can be low performing (due to their high commoditization), ephemeral, or insecure by default — simply because automation is hard, and so tradeoffs need to be made.
Dynamic provisioning of volumes for applications can free applications of needing to worry about storage models altogether, leveraging the existing Kubernetes framework to manage volume lifecycles. This automation comes at a small cost: you’ll want to think about binding as well as retention policies for your apps, so that the automated storage provisioning doesn’t break your application requirements.
So let’s think about how this works in the real world, with real apps, when you transition to a production storage model that still is capable of supporting a dynamic provisioning model.
Understanding Binding and Retention Modes
If you’re wondering what step (2) in the sequence outlined above is all about – you’re not alone. Binding mode is an important part of the StorageClass API which many people fail to think about before deployment.
This is where building a custom, dynamic provisioner might be extremely important. Dynamic provisioning is not just a way to provide native storage, but rather, a powerful tool for enabling high-performance workloads in a datacenter with heterogeneous storage requirements.
Let’s consider how we might implement different provisioning strategies for the different workloads outlined in the table above. Each would use different StorageClass semantics for binding mode and retention policy, explained below:
- HDFS/ETL style workloads: You want to store your data on a bare metal disk, and read from that disk, as if it was just a host volume mount. The binding mode for this type might benefit from the WaitForFirstConsumer strategy, which would allow for a volume to be created/attached directly on a node that was running the workload. Since datanodes are a persistent feature of a cluster, and HDFS itself maintains replication for you, your retention policy for this model might be “Delete”. For example, Kafka workloads benefit heavily from this pattern, since durable. local storage is important to a kafka workqueue.
- Cold storage workloads: You want to automate a policy of putting specific translators for storage volumes (for example in Gluster) into workloads running in certain labeled namespaces. All provisioning might be done on-demand, in the cheapest disks available at the time. In this case, you would want to use the Immediate binding strategy, since availability for cold storage is more important than performance. Since cold storage is often for critical data logs that need to be kept for years at a time, you might set the retention policy on these volumes to “Retain”. Don’t run a database on this storage class – it may not support the right operational semantics (for example, certain types of read-aheads, and so on), or latency may be crippling. These share some commonality with our AI workloads – as the performance of the storage isn’t important – but might require cloning, as well.
- Postgres-style workloads: You need dedicated, Solid State Drives that may be several terabytes. As soon as storage is requested, you want to know where your pod is running, so you can reserve an SSD in the same rack or on the same node. Since disk locality and scheduling can significantly affect the performance of these workloads, your storage class for Postgres might use the WaitForFirstConsumer strategy. Since a Postgres database in production often has important transactional history you may choose a retention policy of “Retain”.
- AI Workloads: Your data scientists don’t care about storage, they just want to crunch numbers and need a scratchpad to cache old computations (i.e. building a new model for a large data set may take 5 seconds or so, and you may be doing this for 100’s of 1000’s of datasets, where there is an overlap in various intermediate computations…. data locality isn’t always important as your doing a single file transaction, and Immediate binding could be done for faster pod startups, and similarly a retention policy of Delete would probably be appropriate, since the cost of the initial compute is amortized by the long lifespan of an individual worker, and the cache is probably less relevant over time – so the occasional spring-cleaning on pod restarts is ideal.
Given the variable nature of these storage models, you may need a custom logic for fulfilling volume claims, and you may simply name these volume types (respectively) “hdfs”,”coldstore”,”pg-perf”,”ai-slow”.
Customizing your Dynamic Provisioning with External Provisioners
Clearly, you can’t have a “one size fits all” storage model: dynamic or not.
The emergence of dynamic provisioners as the standard persistent storage tool for large clusters is because of this realization — which happened in the kubernetes community over time: People ultimately would have to craft their own storage models using cloud-native APIs, rather than relying on complex semantics. In fact, this is evident in the API itself, as recycling was once a feature in earlier Kubernetes APIs which has now been deprecated, in favor of custom dynamic storage provisioners.
The obvious case for why you need an external provisioner is to maximize cost/benefit at time of use for a new volume. For example, in each of these cases, we need completely different storage characteristics to maximize cost/benefit.
- AI: Accept high latency, ephemeral storage model.
- Compliance: A high latency, permanent storage model is good enough.
- Logging: A low latency, but still ephemeral model is good enough.
However, even if we had off-the-shelf implementations of these types of volumes, we still may need to build our own external provisioner. Two more granular use cases where we are almost guaranteed to need a custom provisioner might be: Performance-sensitive applications and applications which have special privacy or scrubbing requirements.
There are several reasons why you may want to delete certain parts of a volume, but not all of it. Three examples:
- Compliance and historical data are often important.
- AI and Machine learning workloads also have subtle storage needs which aren’t as binary as ‘delete it all’ or ‘keep it all’.
- And over time, your storage policy may change as disks become full and you need to be more efficient in how you use the remaining space.
So far we’ve discussed why you may want an array of StorageClasses, but we haven’t dove into the details of how custom storage provisioners work.
Now, let’s take a look at how external provisioners work, under the hood – you likely will want to understand at least some of these internals if you need to provide sophisticated storage services to a broad range of applications running in the same cluster.
External provisioners: How they work, and how they are implemented.
There are a few details worth mentioning between how StorageClasses work relative to internal and external provisioners in the Kubernetes ecosystem.
- Internal provisioners (“In-Tree”): these are volumes that Kubernetes itself can create. As CSI moves forward (more on that below), the list of these will decrease over time.
- External provisioners: as shown in the diagram below, these exist in pre-CSI and post-CSI kube distributions. Vendor’s have always had the right to make a provisioner with highly opinionated semantics, outside of the provisioning mechanisms that Kubernetes is natively aware of. External provisioning is the future model for all storage on Kubernetes.
- The “parameters” section in the StorageClass is fully customizable, as we can see in pkg/apis/storage/types.go… Hence, you can put anything you want in it and build your own custom storage controller.
// parameters holds parameters for the provisioner. // These values are opaque to the system and are passed directly // to the provisioner. The only validation done on keys is that they are // not empty. The maximum number of parameters is // 512, with a cumulative max size of 256K // +optional Parameters map[string]string
For example, in an AI scenario, certain computations are generic and can be cached on disk, but most of the data is truly ephemeral and should be deleted. In this case, you would need to implement custom logic to the way you provision new volumes, possibly running a “finalizer” type operation on storage volumes before you make the storage available to the next workload.
Visualizing the way a custom dynamic provisioner for an enterprise might work for a variety of storage classes in the real world (using the above workload examples), we can see that the decision of what to do before, and after a volume is created/deleted is a complex series of steps which has to take into account (1) the performance characteristics (2) the lifecycle semantics and finally make a decision as far as what volume type to create. Once this decision is made, the dynamic provisioner ultimately binds the PVC to a PV and the application can be scheduled.
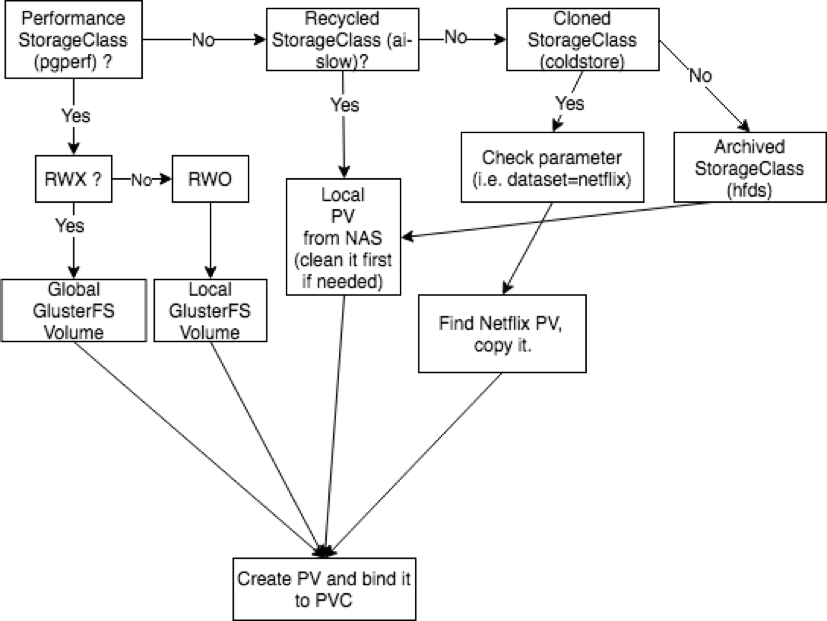
Dynamic provisioning doesn’t actually implement the automatic creation of physical storage, rather, it simply connects the Pod API to a declarative storage model.
This is the motivation for the Container Storage Interface (CSI) storage model. As dynamic provisioning and heterogeneous storage models continue to expand, the need to plug complex physical storage implementations, often times third-party ones which aren’t managed by the open source community, has to move out of Kubernetes itself, and the kubelet needs a way to find and mount these different volume types.
CSI: Providing storage indirection to the Kubernetes API.
CSI tends to confuse a lot of people – in that they expect it to solve a lot of problems. Actually, it doesn’t solve anything immediately for end users of Kubernetes, and in the short term, you should be aware that it might actually make your life harder.
To visualize the difference between CSI and dynamic storage using Storage Classes in-tree, we’ve separated out the “old” way of doing things (in-tree storage, which was handled by the kubelet and the master plane of Kubernetes) from the “new” CSI way of doing things below:
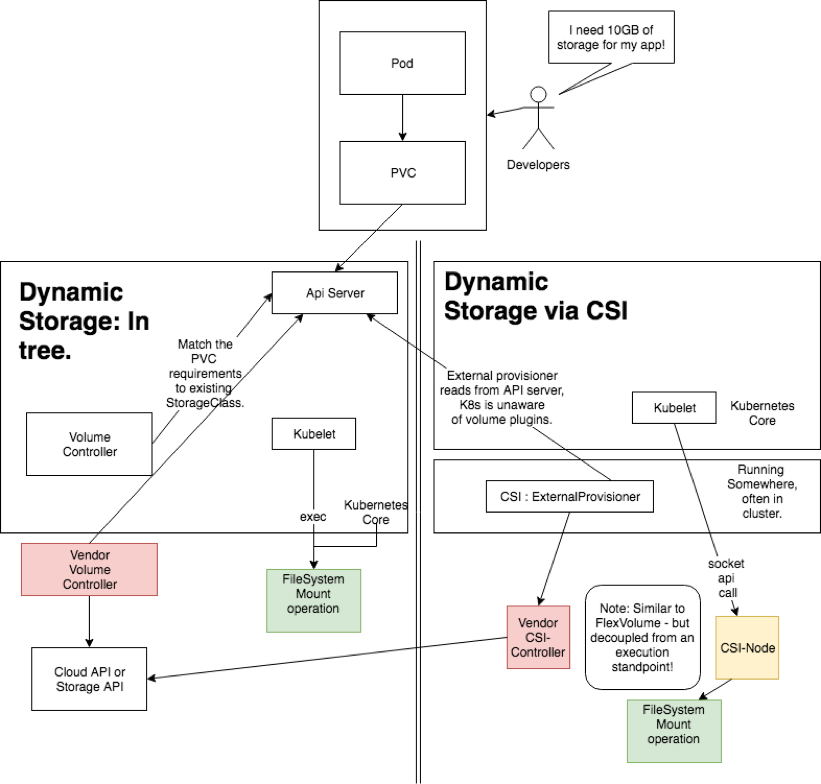
In the above diagram: A developer cares about their pod having storage. The API server receives a request, and dynamic storage fulfills the same requirement in either scenario, albeit much more complex (and decoupled) in a post-CSI universe.
Yes, Storage decoupling is a necessary part of moving to production. As Kubernetes matures, CSI represents the massive undertaking of decoupling storage, entirely, from the Kubernetes master components. This frees vendors to ship storage that satisfies a well-defined interface rather than put vendor-specific storage code into Kubernetes itself.
The Container Storage Interface (CSI) is an interface for implementing persistent volumes, which recently has been promoted to GA providing pluggable storage that is completely unaware of Kubernetes itself. A few things you should note about CSI which can be confusing:
- CSI solves the problem of upgrading storage functionality in Kubernetes without needing to upgrade Kubernetes itself.
- CSI thus requires that you have independent units running in a cluster which are privileged and able to speak the CSI language for attaching storage to a mount point.
- Container native storage does not require CSI in any way — you can run storage in a container and create volumes just as easily without CSI as with it. The only difference is that CSI allows vendors to have complete control over their release cycle.
So, although CSI doesn’t have major effects for end-users, it correlates to a much richer and better product offerings from a wide range of storage vendors in the cloud native space. Expect your storage vendors to ask you if you support CSI on your internal systems, and if not, when you will — because it’s much easier for vendors to give you a good solution post-CSI then pre-CSI.
Putting these concepts together: Combining CSI with Dynamic Provisioning enables declarative storage for pods, on any volume, without any dependencies on Kubernetes. In fact, with CSI you can access your storage using the same APIs without any Kubernetes cluster at all.
Should You Care about CSI?
Anytime you hear about CSI, you hear about how its modular, how its vendor-neutral, and how it can be upgraded out-of-band. These are nice to have, but do you really care? If storage just worked, you probably wouldn’t. Alas, in production, if you’ve used the standard storage volume type in your cloud, you’ve likely seen:
- Slow startup times
- Databases that failed due to disk I/O or size
- Difficulty transferring storage models
- Storage caused permissions issues which needed init pods, fsGroups, supplementalGroups, or SELinux exceptions to be rectified.
- Lack of multitenancy tools for transferring data volumes between pods in different namespaces
So, vendors are continually updating their storage APIs and performance SLAs. To provide the best possible support for Kubernetes, they need to be able to ship storage drivers without needing to wait around to merge code to Kubernetes itself, which is a lengthy process.
At the vendor-level, CSI offers some hope of addressing storage issues in a timely manner. Thus, any Kubernetes data center that needs RAID semantics, security compliant storage for highly sensitive data, or which relies on boutique storage vendors, will undoubtedly have to use CSI in one form or another in the near future.
Read this hands-on guide to using Rook K8s objects to manage a ceph storage.
Dynamic Provisioning, for the Masses
StorageClasses give anyone the ability to build a declarative storage model that works like CSI, and is referenced inside of PVCs (or appended by an admission controller to them.)
But up until CSI, there was no way to force the kubelet to mount storage using custom code that could be bundled, shipped, and lifecycled outside of a Kubernetes distribution. However, I hope in this article, we’ve clarified the orthogonality of volume technologies (like CSI) and dynamic provisioning implementation. Nevertheless, you can still do dynamic provisioning, the trick is to just use Kubernetes volumes which are “in-tree”.
Since CSI is its own beast in and of itself, we’ll focus on dynamic storage, which must be understood fully in order to truly comprehend how CSI will be implemented at data center scale. Don’t worry, we have another article extending this model to CSI just around the corner!
Ultimately, for many people, the conceptual model for reasoning about Kubernetes storage at large scales first should involve separating out security policies, access policies, provisioning policies, and storage technologies and iteratively improving along these dimensions over time.
In the next part of this series, I share a detailed how-to tutorial for observing the inner-workings of Kubernetes storage and tweaking those in a sandbox environment, using minikube.
There’s more:
- Continue to Part 2: Tutorial: Dynamic Provisioning of Persistent Storage in Kubernetes with Minikube
This article originally appeared on The New Stack.
Author




