Enterprise Infatuation with Kubernetes
It seems that everyone is infatuated with Kubernetes. Every organization has an active project with Kubernetes or planning one. When adopting Kubernetes organizations are quickly realizing that many decisions need to be made and that Kubernetes is no simple thing. Some common questions are:
- How will I deploy Kubernetes?
- Where will I deploy Kubernetes?
- Do I want to use public cloud versions of Kubernetes? Are they reliable?
- What Networking model should our organization use? Calico, Weave, Flannel, other?
- How is storage managed and deployed in Kubernetes?
- Once we deploy Kubernetes, what about Day 2 operations?
In this blog we will focus on the first challenge once Kubernetes is up and running: storage.
As we work with large enterprise customers on their container deployments, a few truths begin to emerge. While every customer is looking to standardize on Kubernetes as the standard for container orchestration, enterprise applications, and newer cloud-native applications need all the enterprise add-ons that datacenters provide.
Enterprises across the Fortune 5000 are looking to leverage Kubernetes in two modes, the first as a way of hosting greenfield applications but also for re-architecting and modernizing legacy applications so that they’re Kubernetes-based. Kubernetes offers robust features and APIs that provide high availability, scalability, support for running portable containers, and for deployment concerns such as rolling upgrades, canary deployments, etc.
Storage is critical for real-world pod-based infrastructure. Container files are transient in nature which means that on termination or crashing, all user data is lost. Also, containers organized into a pod read to share files and data assets. The Volume abstraction accounts for both scenarios.
Therefore one of the key considerations for Kubernetes is enterprise storage support. Applications running in containers need to perform a range of data management tasks and CRUD functions. Thus there is a wide range of persistent storage paradigms that Kubernetes needs to support. Storage has to be a first-class citizen for running legacy applications in Relational Databases, Message Queues, NoSQL databases etc.
The Kubernetes project at CNCF has helped incubate the CSI (Container Storage Interface) to enable a range of 3rd party storage vendors (SP) to develop a standard plugin for their product that is CSI API compliant. Once created, this should integrate seamlessly across a number of container orchestration (CO) systems such as Kubernetes, Mesos etc that implement the CSI.
Enter Platform9 Managed Kubernetes (PMK)
Platform9 offers the industry’s only Kubernetes managed service. The Platform9 Managed Kubernetes (PMK) simplifies and addresses the above challenges for deploying and managing Kubernetes clusters across any infrastructure or cloud. PMK allows for simple deployment of Kubernetes clusters, scaling these clusters, monitoring, upgrading and has a first class service for troubleshooting these deployments. If your organization is just dipping your toe into the Kubernetes ecosystem with your first K8s clusters or have hundreds of Kubernetes clusters deployed, Platform9 can manage these environments.
Deploying Kubernetes on Platform9
I have deployed Kubernetes on Platform9 many times. I wanted to create a new environment for testing storage and Platform9 Managed applications. I set up seven physical servers in our datacenter. Installed Ubuntu 16.04 and was ready to install the Kubernetes Cluster.
- I downloaded the Platform9 Agent and installed it on each server
- Registered the Agent for Platform9 Managed Kubernetes
- Followed the Platform9 Install wizard and created a Kubernetes Cluster.

Simple! Kubernetes up and running in 10 minutes.
Once Kubernetes has been deployed and development teams start using the new environments one of the first challenges that is asked is: “How do I solve persistent storage?” This is the first and a very common challenge that organizations are facing. While dev teams may want to write 12-factor stateless applications, there will be requirements to manage stateful datasets when stateful services like databases, queues, key-value storage, big data and machine learning are running on Kubernetes. The question about storage will come up, it’s just a matter of time, and it will need to be solved in order for organizations to be successful on their Kubernetes journey.
Storage in Kubernetes is complex, from the Kubernetes documentation, there are many types of storage and they can change from cloud provider to cloud provider:
- Volumes
- Persistent Volumes
- Volume Snapshots
- Storage Classes
- Volume Snapshot Classes
- Dynamic Volume Provisioning
PMK offers complete flexibility across all the above decisions that need to be made when deploying K8s. However, when combined with Portworx the storage decision is greatly simplified.
Looking for a comparison of strage providers? Read – Compare Top Kubernetes Storage Solutions: OpenEBS, Portworx, Rook, & Gluster
Enter Portworx – It just works!

After what seemed to be hours of time with the Google machine and reading Kubernetes documentation about storage I ran into Portworx, which provides a solution for Kubernetes storage. I later even discovered that Portworx is a Platform9 partner. Already having deployed Kubernetes and excited to deploy some applications on my newly created Kubernetes cluster I needed a simple, fast solution to provide storage to my containers.
From the Portworx website:
“Portworx is the cloud native storage company that enterprises depend on to reduce the cost and complexity of rapidly deploying containerized applications across multiple clouds and on-prem environments.
With Portworx, you can manage any database or stateful service on any infrastructure using any container scheduler. You get a single data management layer for all of your stateful services, no matter where they run. Portworx thrives in multi-cloud environments.”
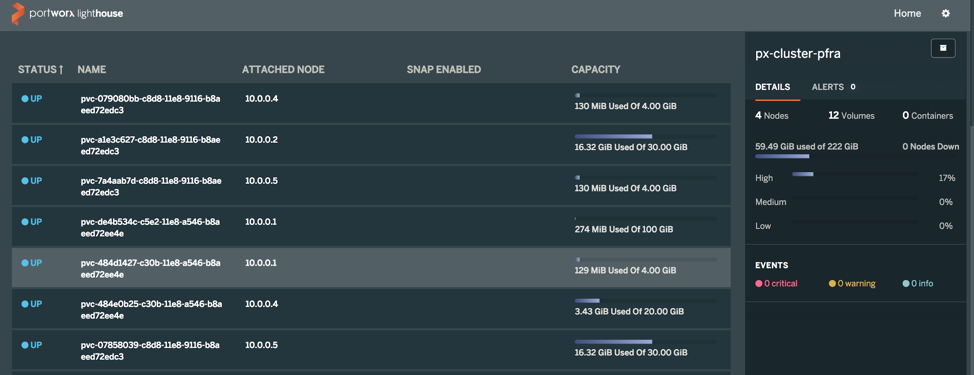
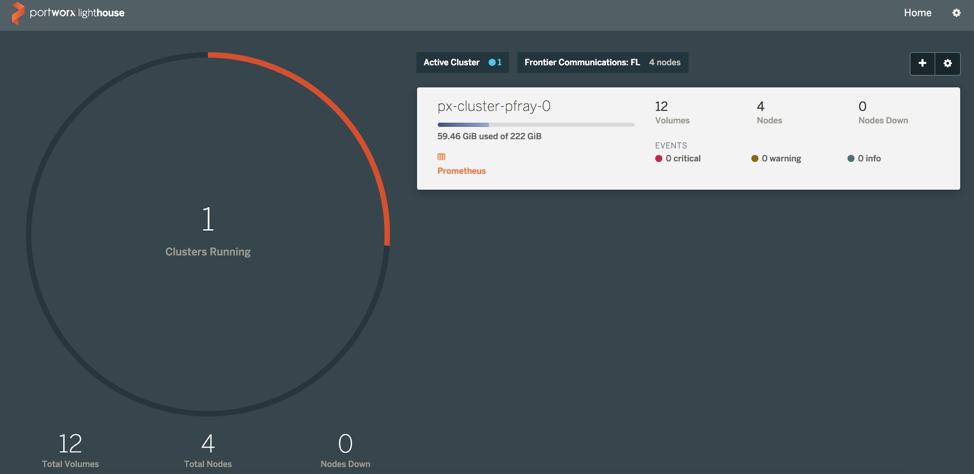
In my environment, I have seven servers that I used Platform9 to deploy a Kubernetes cluster with three master nodes and four workers. After a few clicks of the mouse, I navigated through the Portworx documentation to the “Install on Kubernetes – all other distributions” page. I clicked the “Generate a Spec” link.
I was prompted for:
- Etcd details. I chose Portworx hosted – because that was easier than installing my own and I didn’t want to use my Kubernetes etcd.
- Selected use the “on-prem” storage and use unmounted volumes. This was a great option for me as I already had 4 50gb unmounted volumes on my worker nodes.
- I selected default values for the networking
- Finally, under advanced settings I selected to enable the UI and Stork which is a Kubernetes scheduler extension created by Portworx to enable hyperconvergence of pods and storage, as well as cross-cloud migrations.
OK. This seems too easy to be true. It just what I was looking for. I was presented a spec.yaml which I downloaded and executed:
[code]Kubectl apply -f spec.yaml[/code]
That couldn’t have been easier. After waiting for some time for all the docker layers to download I had a complete up and running Portworx environment.
Get hands on with the PortWorx CSI in our managed kubernetes, with this step by step guide.
Conclusion
The bottom line, in a matter of about 30 minutes I was able to install a complete Kubernetes cluster with Platform9 Managed Kubernetes and have a fully functional storage solution. I think the best description of these two tools working together would be described as “Simplicity in motion”.
After everything was installed I wanted to test this solution to ensure dynamic PVC’s were in fact working and usable by my Kubernetes Cluster. So I decided to install some applications that require the use of persistent storage.
I installed:
- Minio – Opensource AWS S3 environment for your local datacenter
- Jenkins-x – Opensource CI/CD pipeline environment
- Prometheus – Opensource Kubernetes Monitoring
- Grafana – Opensource graphing engine I used as a front end for Prometheus
- EFK Stack – Kubernetes Logging and Monitoring: The Elasticsearch, Fluentd, and Kibana (EFK)
After a half day, I have a highly available Kubernetes cluster running in Platform9 Managed Kubernetes with Platform9 Managed applications and Portworx fully functional. I never had a worry about my storage environment.