
In any enterprise-grade cloud offering, Virtual Machine High Availability (HA) is a must have feature for ensuring application availability despite infrastructure failures. Architecting cloud with consideration to HA helps protect cloud native as well as traditional applications against failures. Until now, HA features were available only on virtual infrastructures like VMware, Hyper-V, etc. With Platform9 managed OpenStack, customers can now use the same capability in their KVM environment as well.
Modern applications use multi-tier architecture and data sharding to provide consistent performance and tolerance to failures. The application can scale out or scale in based on the request load. Failures of individual instances typically do not impact modern workloads. However, large scale datacenter failures can still impact the availability of such applications. Cloud scale datacenters are architected with consideration to hardware failures. OpenStack allows admins to designate failure domains by a construct called Availability Zone (AZ). Platform9 managed OpenStack protects cloud native applications against such failures by placing workloads across multiple AZs.
Traditional applications assume always available infrastructure. The application architecture cannot tolerate hardware failures. Virtual machine or hypervisor failures impact availability of such applications. With Platform9 managed OpenStack, such applications can be protected as well. If the application VM crashes or the underlying hypervisor node goes down, such VMs can be relocated to a new host with Platform9 HA capability.
Protecting Cloud Native Applications
Platform9 managed OpenStack helps infrastructure admins and application developers plan for major hardware failures. Depending on the design of a datacenter, an AZ can be a server chassis, a rack or even the entire datacenter environment. The application developers can design their cloud native applications to tolerate AZ failures.
OpenStack provides a autoscaling group construct to facilitate automatic scaling of cloud ready apps based on resource utilization. With Platform9’s HA feature, the autoscaling group have been extended to add an AZ requirement as well. For example, the following template describes an autoscaling group with availability

A heat template describes the blueprint of a scale out application. As the workload across instances increases, more application instances are deployed. With Platform9, the developers can specify the AZs to use for deploying the application instances. The AZs can be specified as a comma separated list with “availability_zones” property. Platform9 managed OpenStack ensures that at least one app instance is deployed per AZ specified in the template. The following failure events are handled
- Host failure in AZ: A new instance of the application is started on another host in the same AZ
- AZ wide failure: The application instances in other AZs continue to serve user requests. The cloud native application does not experience any disruption.
Protecting Traditional Applications
Platform9 Managed OpenStack extends HA to traditional applications. AZs are used as a construct for protecting legacy applications as well. Cloud admins can enable HA on an availability zone as shown below.
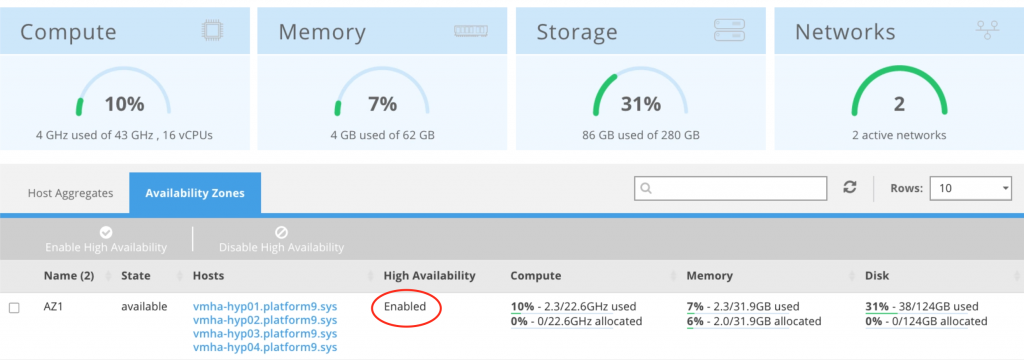
To recover a VM on a failed node, shared storage is needed. All nodes in a HA cluster should use the same shared storage with identical VM storage paths to properly recover VMs on a failed node.
Upon enabling HA on an AZ in OpenStack, Platform9 deploys distributed clustering services on all KVM nodes in that AZ. The clustering services use Gossip protocol to keep track of all nodes in the cluster. The distributed cluster has following advantages over the traditional approach of using heartbeats to health check nodes-
- Gossip protocol can discover failures reliably and quickly compared to heartbeat based methods. The VM downtime is much shorter.
- It can detect tricky failures like network partitions that cannot be detected with heartbeats.
In the event of a node failure, it is fenced off and removed from the cluster. As shown below, All VMs running on that node are restarted on other nodes in the same AZ.

Depending on the size of AZ and the expected number of VM failures, spare capacity should be provisioned to recover VMs from failed nodes. Platform9 makes it easy to configure spare capacity.
Platform9 can manage the distributed cluster automatically. No manual configuration is needed upon failure. The cluster is maintained automatically as hypervisor nodes get added or removed from the AZ.
To summarize, Platform9 managed OpenStack provides seamless HA capability for today’s enterprises. By addressing the unique HA requirements for cloud ready as well as legacy applications, it makes it easy to transition to cloud without compromising the availability of workloads. See below for a demo of this HA capability.
References:
- Gossip Protocol: https://en.wikipedia.org/wiki/Gossip_protocol
- Consul: https://www.consul.io/docs/index.html
- Distributed Cluster Orchestration in OpenStack: http://pf9.io/vmha-blueprint
- Masakari (VM HA service in OpenStack): https://launchpad.net/masakari
- Source Code: http://pf9.io/vmha-repo



