
There are several SaaS and open-source solutions that have the capability to manage multiple, disparate Kubernetes clusters – regardless of the specific distribution or what hosted offering is in play – as long as it is a certified Kubernetes platform. Kubernetes multi-cluster management focuses broadly on giving a single view to interact with, and report on each and every separate cluster under management.
Kubernetes Federation takes this concept of multi-cluster management a step further, and introduces the capabilities to have a master configuration that is managed through a single API in the host cluster, and have all or part of that configuration applied to any clusters that are members of the federation.
Kubernetes Multi-cluster vs. Multi-tenant vs. Federation
In the world of Kubernetes, there are some concepts which are similar, and can share some features but are distinct deployment models. The most basic deployment model is of a single cluster that is used by one development team where no partitioning of any kind is needed. Multi-cluster management is the ability to gain visibility and control over many of these separate custers. While single-cluster deployment this is the easiest deployment path, it is not the best use of compute resources as it requires having all of the overhead associated with a cluster for each and every team/use. This is amplified when security and quality assurance teams also want their own place to test and deploy the same applications.
Kubernetes Multi-tenancy is the ability to have multiple distinct areas (usually namespaces) within a single cluster where quotas and security policies can be applied at the boundaries to improve overall resource utilization and simplify the overall infrastructure required to support an environment.
There are times where you still need to have multiple separate clusters in play whether it is to separate development and production, run sensitive workloads, or even across multiple data centers. This scenario can still have multi-tenancy in some or all of the clusters, but it has become a multi-cluster deployment. Multi-cluster management allows for a single interface which can see and control aspects of every cluster that is connected to the multi-cluster management plane.
Kubernetes Federation extends some attributes Multi-cluster, but does not cover all the multi-cluster scenarios. When multiple clusters are federated then they actually share pieces of their configuration which is managed by what is called the host cluster and sent to the member clusters of the federation. The benefit of having the high order parts of a configuration shared is that any resources configured to take advantage of the federation will treat all member clusters as a single distributed cluster with oversight by the host cluster.
Common uses for Kubernetes federation
One of the most common scenarios where Federation is desirable is to scale an application across multiple data centers. The application is packaged in a deployment which is set to leverage the federation and it equally spreads out its desired number of replicas across worker nodes in all the member clusters. Since not all the configuration has to be pushed from the host to all members, it allows for local variables in each member cluster to be supplemental to the federated configuration. With this, you can accommodate cluster-specific things like domain names and network policies that can be different per environment.
History of Kubernetes Federation
Kubernetes Federation is an approach released and managed by the multicluster Special Interest Group (SIG) under the umbrella of the Kubernetes project in the CNCF. Version 1 of the standard was originally maintained by the core Kubernetes team when it was released in Kubernetes 1.5 version until about version 1.8, at which point it was transitioned to the SIG. The SIG realized the approach wasn’t in line with how configuration management was moving in the main Kubernetes distributions and started working on version 2, which is a complete rewrite – currently in beta – and works on Kubernetes versions 1.13 and newer.
Kubernetes Federation v2 is referred to as “KubeFed,” and it supports a new standard approach that leverages commonly-used components in Kubernetes, like CRDs. The SIG has a kubefedctl CLI tool in early stages of development on GitHub that will manage the configuration within a federation.
The basic architecture of Kubernetes Federation
The core concept behind Kubernetes Federation is the host cluster that contains any configuration that will be propagated to the member clusters. The host cluster can be a member and run real workloads too, but typically organizations will have the host cluster as a standalone cluster for simplicity.
All cluster-wide configurations are handled through a single API, and define both what is in scope of the federation and what clusters that piece of configuration will be pushed too. The details of what is included in the federated configuration are defined by a series of templates, policies, and cluster-specific overrides.
The federated configuration manages the DNS entries for any multi-cluster services in addition to needing access to all the member clusters to create, apply, and remove any configuration items including deployments. Typically every deployment will have its own namespace, which will be consistent across the member clusters.
So, for example, a Kubernetes Federation is set up with three-member clusters. The first runs in Google Cloud in Canada, the second in Azure in Singapore, and the third in IBM’s UK cloud. You have the flexibility to deploy application A in namespace test-app1 across gke-canada and ibm-uk, while application B will be deployed in gke-canada and aks-singapore.
For a more detailed breakdown of the Kubefed architecture see the project’s GitHub.
Setting up Kubernetes Federation
As with all things Kubernetes, the concept is simple, but the execution can get as complicated as you want to make it. In the “happy day scenario,” if all the prerequisites are in place in the clusters that will be federated, it can be as simple as a few commands. To see what is possible, KubeFed Katacoda takes just under 30 minutes to show off a simple use case.
The basic flow picks the cluster that will become the host cluster, configures the roles and service accounts that are needed, and deploy the federation control plane. From the documentation you can also see there is a HelmChart available for the installation, if you prefer.
Create RBAC for Helm
$ cat << EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
EOF
$ helm init --service-account tiller
Install KubeFed Control Plane via Helm
$ helm repo add kubefed-charts \ https://raw.githubusercontent.com/kubernetes-sigs/kubefed/master/charts $ helm install kubefed-charts/kubefed --name kubefed --version= \ --namespace kube-federation-system
Configuration Flow within a Kubernetes Federation
Now that Federation is up and running between a couple of Kubernetes clusters, it is time to start using the capabilities to simplify service and application administration. The types of objects that leverage Federations most often are deployments and services that point at the applications contained in those deployments.
The first two pieces of the puzzle that we need are a central namespace created on the host cluster to contain the federated deployment resources and a federated namespace with the same name on each cluster that will contain the deployed resources:
apiVersion: v1
kind: Namespace
metadata:
name: nginx-test
---
apiVersion: types.kubefed.io/v1beta1
kind: FederatedNamespace
metadata:
name: nginx-test
namespace: nginx-test
spec:
placement:
clusters:
- name: cluster1
- name: cluster2
- name: cluster3
The functional piece of the puzzle is the actual federated deployment of nginx that will create four replicas that will be spread evenly over the clusters it has specified and will use the nginx-test namespace on all clusters:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: nginx-test
namespace: nginx-test
spec:
template:
metadata:
labels:
app: nginx
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
placement:
clusters:
- name: cluster1
- name: cluster3
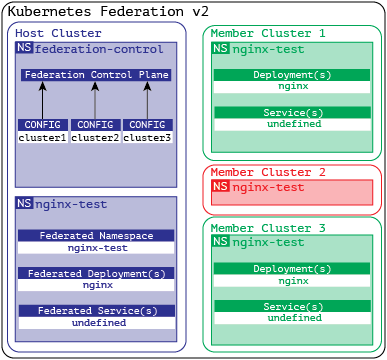
The diagram below shows how the configuration is propagated across the live clusters which are Federated. You’d notice the configuration didn’t flow to the cluster that was excluded from it. While cluster2 has the namespace it does not have any deployed artifacts which means that simply because the namespace exists on the member cluster does not mean everything automatically propagates into it without being declared in the federated deployment.
Next Steps
While Kubernetes Federation looks promising and is well on its way, it is not generally available yet. So for now, only those comfortable with the bleeding edge will be deploying it in production. To simplify multi-cluster and multi-environment management, consider an enterprise Kubernetes platform, such as Platform9 Managed Kubernetes- to alleviate the operational burden that comes with Kubernetes at scale.
To stay current with the status of KubeFed, the special interest group has mailing lists and regular meetings, which can be found on their official page.



