
Modern enterprises that need to ship software are constantly caught in a race for optimization – whether that is speed (time to ship/deploy), ease of use, or, inevitably, cost. What makes this a never-ending cycle is that these goals are often at odds with each other. The choices that organizations make usually inform what they’re optimizing for. At a fundamental level, these are the factors that drive, for example, whether enterprises use on-premises infrastructure or public clouds, open-source or closed source software, or even certain technologies – like containers vs. virtual machines.
Let’s take a deeper look into the factors that drive this cyclic nature of cloud infrastructure optimizations, and how enterprises move through the various stages of their optimization journey.
The 3 stages of infrastructure cost optimization for large enterprises
1. Legacy, on-premises infrastructure
Large enterprises often operate their own datacenters. They’ve already optimized their way here by getting rid of large houses of racks and virtualizing a lot, if not all, of their workloads. The consolidation and virtualization resulted in great unit economics. This is where we start our journey.

Unfortunately, their development processes are now starting to get clunky: code is built using some combination of build automation tools, and home-grown utilities, and usually involves IT teams to requisition virtual machines to deploy.
In a world where public clouds offer developers the ability to get all the way from code to deploy and operate within minutes, this legacy process is too cumbersome, even though this infrastructure is presented to the developers as a “private cloud” of sorts.
The fact that the process takes so long has direct impact on the business outcomes because it greatly delays cycle times, response times, the ability to release code updates more frequently, and – ultimately – time to market.
As a result, enterprises look to optimize for the next challenge: time to value.
Public clouds are a great solution here, because there is no delay associated with getting the infrastructure up and running. No requisition process is needed, and the entire pipeline from code to deploy can be fully automated.
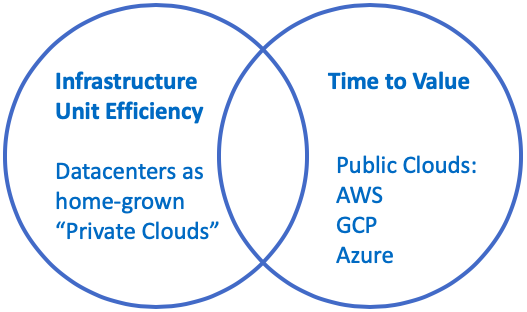
2. Public cloud consumption
At this point, an enterprise has started using public clouds (typically, and importantly, a single public cloud) to take advantage of the time-to-value benefit that they offer.
As this use starts expanding over time, more and more dependencies are introduced on other services that the public cloud offers. For example, once you start using EC2 instances on AWS, pretty quickly your cloud-native application also starts relying on EBS for block storage, RDS for database instances, Elastic IPs, Route53 and many others. You also double down further by relying on tools like CloudWatch for monitoring and visibility.
In the early stages of public cloud use, the ease of use when going with a single public cloud provider can trump any other consideration an enterprise may have, especially at a reasonably manageable scale. But as costs continue to grow with increased usage at scale, cost control becomes almost as important.
You then start to look at other cloud cost management tools to keep these skyrocketing costs in check – ironically from either the cloud provider itself (AWS Budgets, Cost Explorer), or from independent vendors (Cloudability, RightScale and many others). This is a never-ending cycle, until – at some point – the public cloud infrastructure flips from being a competitive enabler to a commodity cost center.
At a particular tipping point, the linear cost of paying per VM becomes more expensive than creating and managing an efficient datacenter with all its incumbent costs. A study by 451 Research pegged this tipping point to be at roughly 400 VMs managed per engineer, assuming an internal, private IaaS cloud.
Thus, there is a tension between the ease of using as many services as you can from a one-stop-shop and the cost of being locked into a single vendor. The cost associated with this is two-fold:
- Being at the mercy of a single vendor, and subject to any cost / pricing changes made here. Being dependent on a single vendor means that your leverage is reduced in price negotiations, not to mention being subjected to further cross / up-sells to other related offerings that further perpetuates the lock-in. This is an even larger problem with the public cloud model because of the ease with which multiple services can proliferate.
- Switching costs. Moving away from the vendor incurs a substantial switching cost that keeps consumers locked in to this model. It also inhibits consumers’ ability to choose the right solution for their problem.
In addition to vendor lock-in, another concern with the use of public clouds is the data security and privacy issues associated with off-premises computing that may, in itself, prove to be a bridge too far for some enterprises.
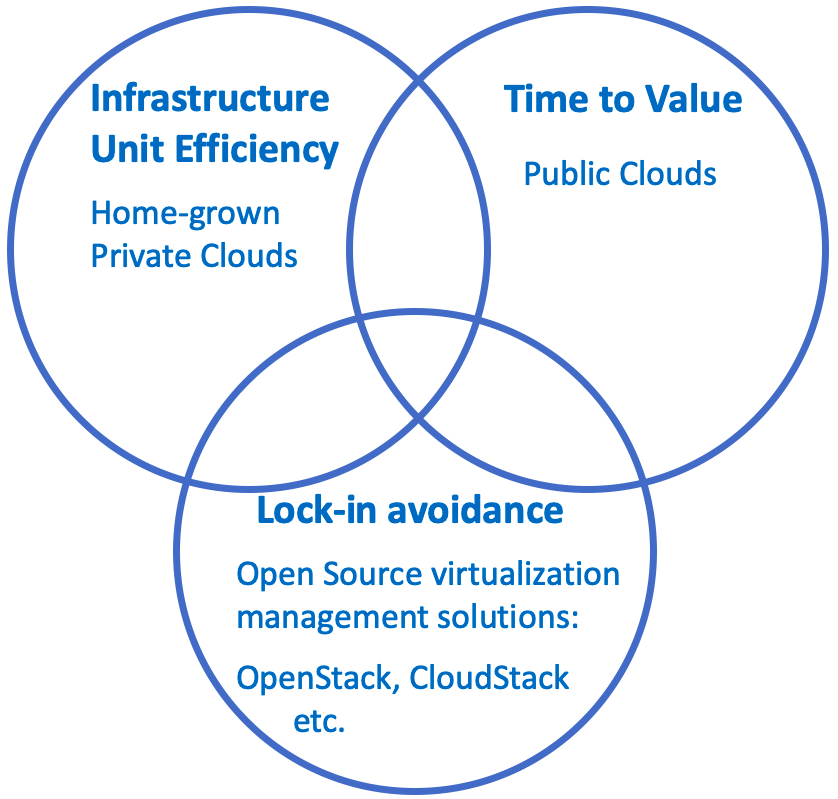
One of the recent trends in the software industry in general, and cloud infrastructure solutions in particular, is the rise of open-source technology solutions that help address this primary concern of enabling ease of use alongside cost efficiency, and lock-in avoidance.
Open-source software gives users the flexibility to pay vendors for support – either initially, or for as long as it is cost-effective – and switch to other vendors or to internal teams when it is beneficial (or required, for various business reasons).
Note that there are pitfalls here too – it is sometimes just as easy to get locked into a single open-source software vendor as it is with closed-source software. A potential mitigation is to follow best practices for open source infrastructure consumption, and avoid vendor-specific dependencies (or ‘forking’- in the case of open source) as much as possible.
3. Open Source Hell
You’ve learned that managing your datacenter with your own homegrown solutions kills your time-to-value, so you tried public clouds that gave you exactly the time-to-value benefit you were looking for. Things went great for a while, but then the scale costs hit you hard, made worse by vendor lock-in, and you decided to bring computing back in-house. Except this time you were armed with the best open-source tools and stacks available that promised to truly transform your datacenter into a real private cloud (unlike in the past), while affording your developers that same time-to-value benefit they sought from the public clouds.
If you belong to the forward-looking enterprises that are ready to take advantage of open-source solutions as a strategic choice, then this should be the cost panacea you’re looking for, right?
Unfortunately, most open source frameworks that would be sufficient to support your needs are extremely complex to not only setup, but manage at a reasonable scale.
This results in another source of hidden operational costs (OPEX) – management overhead, employee cost, learning curve and ongoing admin – which all translate to a lot of time spent -not only on getting the infrastructure to a consumable state for the development teams, but also keeping it in that state. This time lost due to implementation delays, and associated ongoing maintenance delays, is also costly – it means you cannot ship software at a rate that you need to stay competitive in your industry.
Large enterprises usually have their own data-centers, and administration and Operations teams, and will build out a private cloud using open-source stacks that are appropriately customized for their use. There are many factors that go into this setting this up effectively, including typical data-center metrics like energy efficiency, utilization and redundancy. The cost efficiency of going down this path is directly dependent on optimizing these metrics. More importantly, however, this re-introduces our earliest cost factor: the bottom-line impact of slow time-to-value and the many cycles and investment spent not just on simply getting your private cloud off the ground, but having it consumable by development teams, and in an efficient manner.
You have now come, full circle, back to the original problem you were trying to optimize for!
The reason we’re back here, is that the 3 sources of cost we’ve covered in this post – lock-in, time-to-value and infrastructure efficiency – seemingly form the cloud infrastructure equivalent of the famous CAP theorem in computer science theory. You can usually have one or two of them, but not all 3 simultaneously. In order to complete the picture, let’s introduce solutions that solve for some of these costs together:
Approaches to the CAP theorem problem of and Cloud Infrastructure Costs:
Enabling Time-to-value AND Lock-in avoidance (in theory):
This is where an almost seminal opportunity in terms of cloud-infrastructure standardization comes in: open-source container orchestration technologies, especially Kubernetes.
Kubernetes offers not only an open-source solution that circumvents the dreaded vendor lock-in, but also provides another layer of optimization beyond virtualization, in terms of resource utilization. The massive momentum behind this technology, along with the community behind it, has resulted in all major cloud vendors having to agree on this as a common abstraction for the first time. Ever. As a result, AWS, Azure, and Google Cloud all offer Managed Kubernetes solutions as an integral part of their existing managed infrastructure offerings.
While Kubernetes can be used locally as well, it is notoriously difficult to deploy and even more complex to operate at scale, on-premises. This means that, just like with the IaaS solutions of the public clouds, to get the fastest time to value out of the open source Kubernetes, many are choosing to use one of the Kubernetes-as-a-Service (KaaS) services offered by the public cloud- hence achieving time to value and (possible) lock-in avoidance – since, presumably, you’d be able to port your application at any point to a different provider.
Only, chances are – you never will. In reality, you’re risking being dependent, once more, on the rest of the cloud services offered by the public cloud. The dependency is not just in the infrastructure choice – but is felt more in the application itself and all the integrated services. Goes without saying, too, that if you go with a Kubernetes service offered by the public clouds, then these solutions have the same problem that IaaS solutions do at scale in the public cloud – around rising costs – along with the same privacy and data security concerns.
In practice, the time-to-value here is essentially tied to Kubernetes familiarity (assuming you’re going with the public cloud offering) or advanced operational expertise (assuming you’re attempting to run Kubernetes at scale, on-prem).
From the perspective of Day-1 operations (bootstrapping) – If your team is already familiar with, and committed to, going with Kubernetes as their application deployment platform, then they can get up and running quickly. There is a big caveat here – this assumes your application is ready to be containerized and can be deployed within an opinionated framework like Kubernetes. If this isn’t the case there is another source of hidden costs that will add up: re-architecture or redesigning of the application to be more container-friendly. (Side note: Fortunately, there are other enabling technologies that aim to reduce this ramp-up time to productivity or re-design. A class of these is serverless or FaaS technologies, built on top of Kubernetes – like the open source fission, designed to accelerate time-to-value with Kubernetes.)
The complexities of Day-2 operations with Kubernetes for large-scale, mission-critical, applications that span on-premises or hybrid environments are enormous, and a topic for a future blog post. But suffice it to say that if you’re able to deploy your first cluster quickly with any open source tool – for example the likes of Rancher or Kops or others – to achieve fast time-to-value for Day-1, you’re still nowhere close to achieving time-to-value as far as day-2 operations are concerned. Operations around etcd, networking, logging, monitoring, access control, and all the many management burdens of Kubernetes for enterprise workloads have made it almost impossible to go on-prem without planning for an army of engineers to support your environments, and a long learning curve and skills gap to overcome.
Enabling Time-to-value AND Infrastructure Efficiency:
This is where hyper-converged infrastructure solutions come in. These solutions offer the promise of better time-to-value outcomes because of their turn-key nature, but the consumer pays for this by, once again, being locked into a single vendor and their entire ecosystem of products – which makes these solutions more expensive. For example, Nutanix offers not only their core turnkey hyper-converged offering, but also a number of “Essentials” and “Enterprise” services around this.
Enabling Infrastructure Efficiency AND Lock-in Avoidance (in theory):
We can take an open-source approach to hyper-converged infrastructure as well, via solutions like Red Hat HCI, for example. These provide the efficiency promise of hyper-converged solutions, while also offering an open-source alternative to single-vendor lock-in. Like any other complex open-source infrastructure solutions, though, they suffer from a poor time-to-value for consumers.
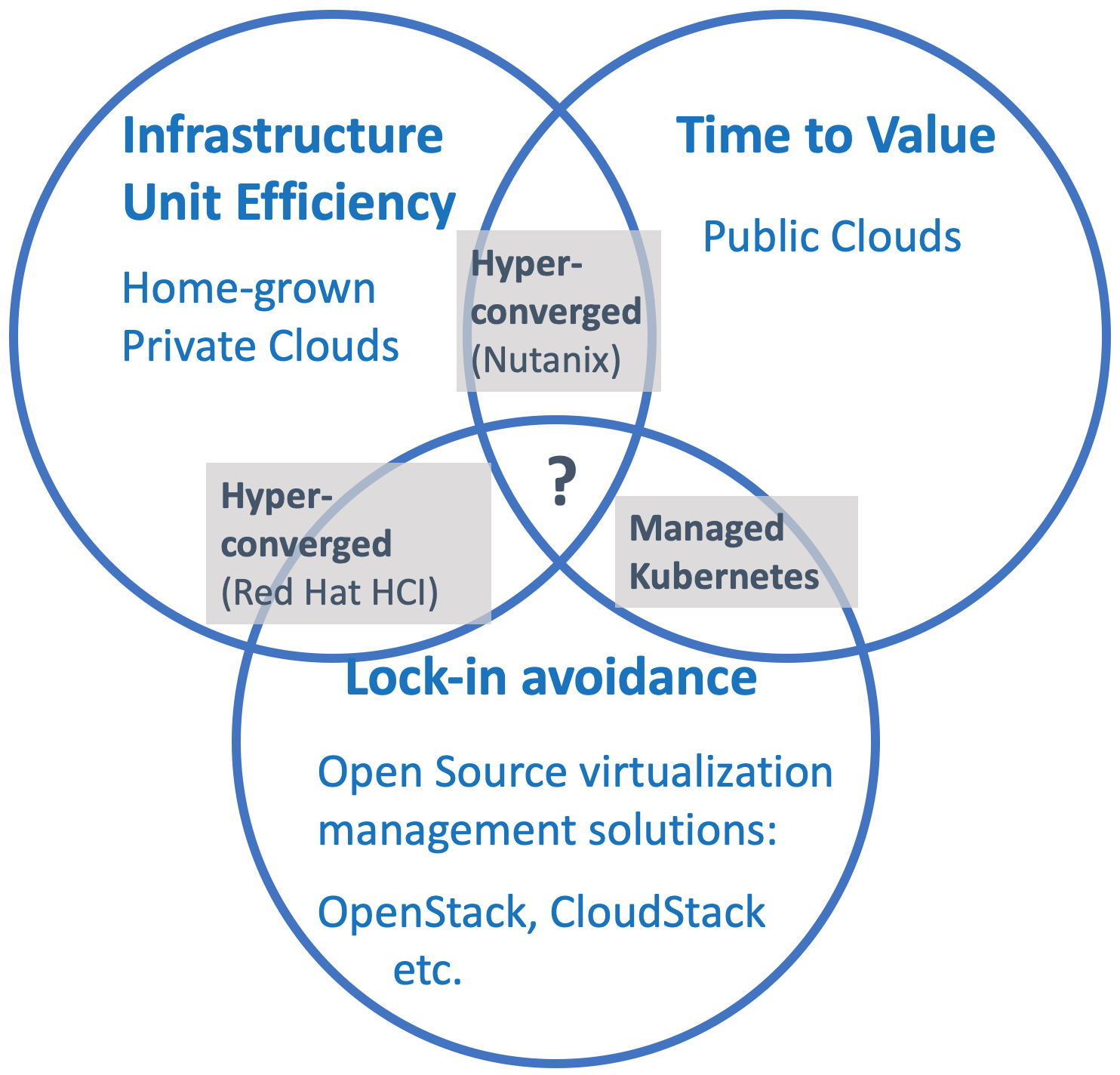
Hybrid Cloud Efforts and Infrastructure Costs Optimization
This, then, is the backdrop against which most “hybrid cloud” efforts are framed – how to increase time to value and enable portability between environments, while improving unit efficiency and data center costs.
Most hybrid cloud implementations end up being independent silos of point solutions that, once more, can only optimize against one or two of the CAP theorem axes. These silos of infrastructure and operations have further impact on overhead, and hence cost, of management.
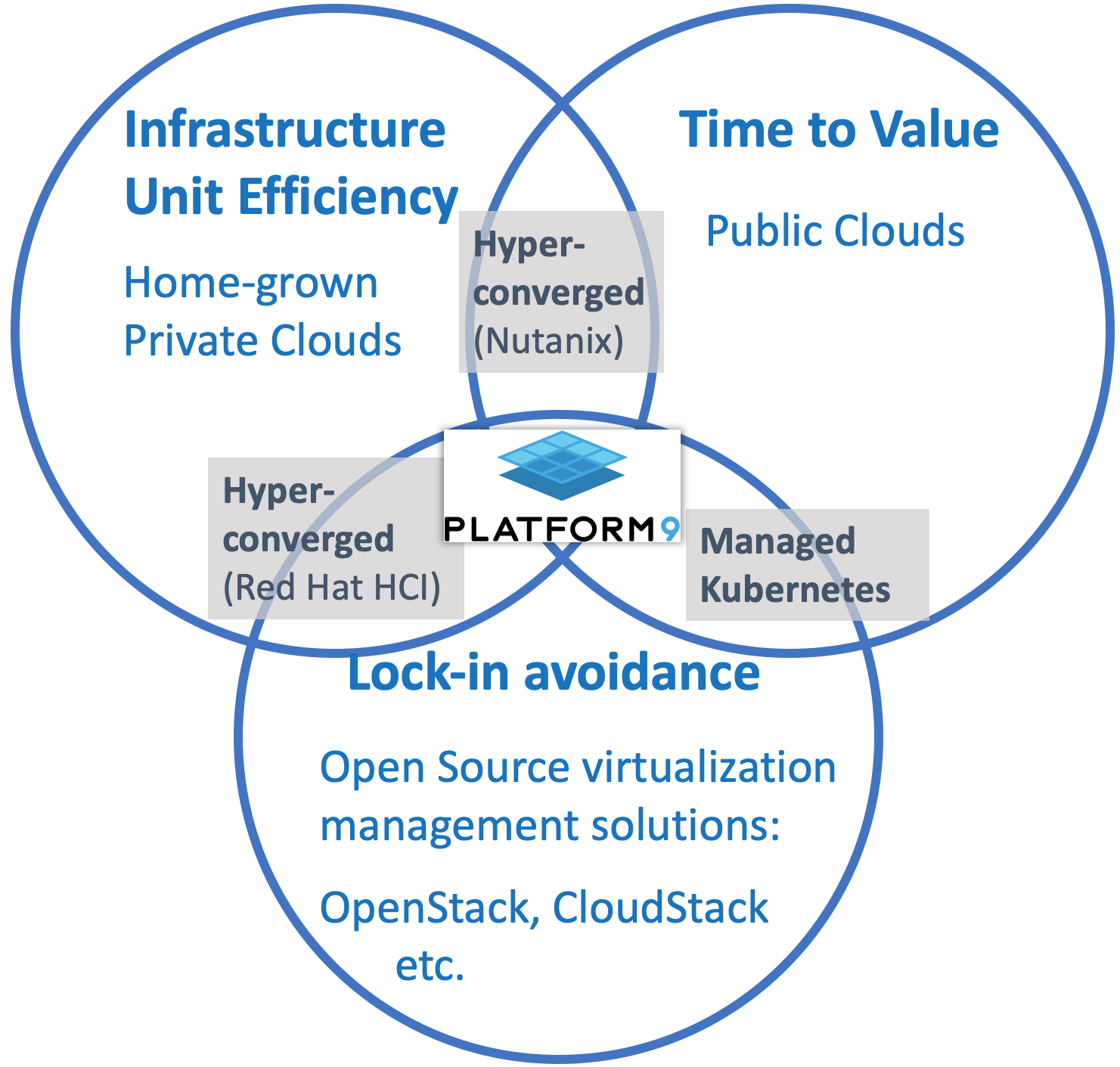
An Ideal Solution: Does one exist?
Breaking this cloud infrastructure oriented CAP theorem would require a fundamentally different approach to delivering such systems. Taking all of this into account, our ideal solution would need to represent the culmination of open-source, public cloud, and datacenter infrastructure – or, in essence, “Cloud-managed Infrastructure” that delivers the time-to-value, user experience and operational model of the public cloud on hybrid data centers too, utilizing open infrastructure to ensure portability and future-proof for innovation.
A hybrid cloud solution designed around these key tenets would provide the following benefits:
- Best of breed open-source stacks to provide a breadth of services, like OpenStack, Kubernetes, and fission – to address vendor lock-in, while also satisfying the needs of developers and modern applications
- Like public clouds, delivered as a SaaS-managed system that is quick to not only get started with, but also maintain, because the operational SLA is not owned by an expensive in-house team but rather guaranteed by the service, ensuring time-to-value.
- Deploying full-fledged software-defined compute, networking, block storage components in this SaaS managed manner – to address datacenter efficiency across all environments.
Shameless plug:
This is why Platform9’s hybrid cloud solution consists of managed open source offerings, backed by a strict 99.99% SLA, for virtualized, containerized and serverless workloads that satisfy the above 3 requirements. In fact, in a reflection of the reality that enterprise IT teams face today, we took it a step further – allowing for all of these workloads to also work the same way across both private data-centers and public clouds, to provide a truly cost-efficient, consistent, single-pane-of-glass hybrid cloud solution.
In Summary:
How do you consume cloud infrastructure?
What costs do you want to optimize for?
How do you prepare for the next generation in software delivery innovation?
What’s your strategy to tackle the continued business pressure to release software faster – while reining in cost?
Hit me up with any comments and questions!
![]() This article originally appeared on Cloud Tech
This article originally appeared on Cloud Tech



