
This is the 3rd blog in Chris Jones’s series on scaling Kubernetes for applications, GitOps, and increasing developer productivity. You can read parts 1 and 2 here and here.
Imagine, your engineering team just updated a project plan showing a three-week delay. The cause? Lack of consistency across development and integration environments. You reach out to the stakeholders: Platform Operations, DevOps, and Engineering.
- Platform Operations: “We built an integration environment and handed it off to DevOps.”
- DevOps: “We have multiple integration environments running, but the applications are failing. Engineering is investigating.”
- Engineering: “Each environment is failing for different reasons, and we just noticed critical services have not been deployed; Kafka and Redis. Also, our developers are building local to their workstations and are spending hours reconfiguring their apps for the integration environments.”
The teams tell you that they’re following IaC and GitOps processes and that nothing can be done as they’re each responsible for discrete parts.
The unfortunate truth is that each team is impacted by symptoms of the exact same problem; running cloud-native with yesterday’s tools and processes.
Kubernetes provides the opportunity to develop, test and operate consistently across environments, locations, and clouds. To achieve this the tools and process must focus on delivering infrastructure, plus shared services, plus user access as a whole.
There is a clear similarity between development and production operations – both rely on shared services, both rely on infrastructure, both rely on processes, and both are impacted by outages. However, only production is treated as a single cohesive unit. Be it built piecemeal or not, production operates as a complete environment. Applying the concept of a ‘complete’ environment to engineering and integration environments seems overwhelming, but, “built for cloud-native” tooling simplifies the complexities immensely.
To mitigate the three-week delay, enable your developers to build on complete clusters and create your integration environments from identical configurations.
What is a Complete Cluster
A complete cluster is a Kubernetes environment that is created with all the required functionality (infrastructure, apps, and policies) that make it useful to an end user, with no manual intervention or additional steps – one command, “create,” and done.
For example:
Complete cluster for a Developer
- Infrastructure: The cluster running in Microsoft Azure Singapore, with nodes capable of training AI Models.
- Applications: AI model software. Redis database. Kafka Messaging.
- Policies/Security: Role-based access that allows the developer to edit the AI Model application manifest. Role-based access to exec into Pods. Security that prevents containers running as privileged.
Complete cluster for Testing
- Infrastructure: The cluster running in Microsoft Azure India, with nodes capable of running AI Models
- Applications: AI model software. Redis database. Kafka Messaging. Central Logging.
- Policies/Security: Role-based access cannot be changed. Security that prevents containers running as privileged.
Complete cluster for Production
- Infrastructure: The cluster running in Microsoft Azure India, with nodes capable of running AI Models that can scale down to zero and up to 25
- Applications: AI model software. Redis database. Kafka Messaging. Central logging. Monitoring stack.
- Policies/Security: Role-based access cannot be changed. Security that prevents containers running as privileged. Security that prevents network traffic.
Each user/environment impacts what ‘complete’ is, but the concept remains the same. All a user needs to do is request a cluster, wait as it’s built with all required elements, and immediately start work.
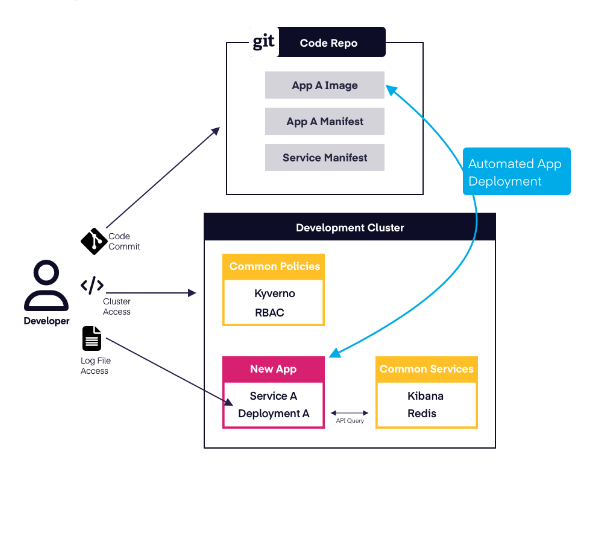
Complete clusters are delivered using automation that supports self-service. In the world of three-week delays, each object, or the group of objects, such as an application, infrastructure service, or policy, are treated as static artifacts. An admin creates the object, potentially stores a version in a Git repository, and deploys it using their tool of choice, and they’re done. The entire process is manual and rigid. A human sets up the Git Repository structure, creates each artifact and manually implements any environment specific changes or overrides. Further, the process serves administrators, and little credence is given to self-service.
Complete clusters are delivered using declarative management and GitOps with a twist!
Complete Cluster
Chris’s series continues with the 4th blog, Build infrastructure for apps, available now.



