Restoring ETCD Backup to Recover Cluster From Loss of Quorum
Problem
ETCD cluster lost its quorum as more than half of the Master Nodes went offline.
Environment
- Platform9 Managed Kubernetes - All Versions
- ETCD
- Docker or Containerd
Cause
Loss of quorum could be a result of Master nodes going offline or loss of connectivity between the master nodes resulting in unhealthy state of cluster.
# /opt/pf9/pf9-kube/bin/etcdctl member list{"level":"warn","ts":"2023-01-14T10:06:19.730Z","caller":"clientv3/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"endpoint://client-x40e9b2f-bdd3-4ac5-8b2a-4026a9df34cd/127.0.0.1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: all SubConns are in TransientFailure, latest connection error: connection error: desc = \"transport: Error while dialing dial tcp 127.0.0.1:2379: connect: connection refused\""}Error: context deadline exceeded......Resolution
Etcd restore is an intricate procedure but the idea is to bring down master count to 1 and restore etcd from backup using etcdctl. Once that is done, we might need to make some manual changes so that it starts up as a new etcd cluster. Once things are back up, we increase the master count one by one i.e. attach nodes.
We encourage our enterprise users to create multi-master setups for HA and redundancy.
There is no API/process in the product currently to do recovery/replacement for a single master node within the cluster.
Restoring a multi-master cluster from an ETCD backup is a complicated process. A detach operation of the affected master node via U/I or API Call followed by an attach operation for a new master node is the preferred approach.
We recommend creating a support request with Platform9 for assistance if needed before initiating any backup-restore operation for quorum loss scenario in multi-master cluster.
Follow below steps to bring the cluster in health state.
- SSH to one of the master node and run the below commands with the root user to set the environment variables.
# docker cp etcd:/usr/local/bin/etcdctl /opt/pf9/pf9-kube/bin# export PATH=$PATH:/opt/pf9/pf9-kube/bin- Check if a latest ETCD Backup is available at default path /etc/pf9/etcd-backup. The path can be different as well if changed. If no backup is available, run the below command to capture an etcd DB snapshot on the same node.
# /opt/pf9/pf9-kube/bin/etcdctl snapshot save </path/to/backup> --cert /etc/pf9/kube.d/certs/etcdctl/etcd/request.crt --key /etc/pf9/kube.d/certs/etcdctl/etcd/request.key --cacert /etc/pf9/kube.d/certs/etcdctl/etcd/ca.crt --endpoints=https://<NODE_IP>:4001 # etcdctl snapshot save /etcd-backup/etcd_db_snapshot.db --cert /etc/pf9/kube.d/certs/etcdctl/etcd/request.crt --key /etc/pf9/kube.d/certs/etcdctl/etcd/request.key --cacert /etc/pf9/kube.d/certs/etcdctl/etcd/ca.crt --endpoints=https://10.128.233.61:4001{"level":"info","ts":1629897685.8847299,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"/home/centos/etcd_db_snapshot.db.part"}{"level":"info","ts":"2021-08-25T13:21:25.905Z","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}{"level":"info","ts":1629897685.905304,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"https://10.128.233.61:4001"}{"level":"info","ts":"2021-08-25T13:21:27.234Z","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}{"level":"info","ts":1629897687.2524045,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"https://10.128.233.61:4001","size":"16 MB","took":1.367479352}{"level":"info","ts":1629897687.2526073,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"/home/centos/etcd_db_snapshot.db"}Snapshot saved at /etcd-backup/etcd_db_snapshot.db- Once the snapshot is captured successfully OR latest backup is found on one of the master node as mentioned in previous step, stop the PMK stack on ALL the nodes part of the cluster_._
$ sudo systemctl stop pf9-{hostagent,nodeletd}$ sudo /opt/pf9/nodelet/nodeletd phases stop- Move the etcd directory to some other path on ALL the nodes part of the cluster_._
$ mv /var/opt/pf9/kube/etcd/* /desination/path/etcd_dir_backup- Restore the ETCD state by using below command on the master node where the snapshot was created and/or backup file is present.
- NODE_IP - IP of the Attached Node. Same can be found out from the "kubectl get nodes" output.
- NODE UUID - Node_UUID corresponds to the value of host_id found in file /etc/pf9/host_id.conf on the Node.
- </path/to/backupfilename> - File present at defined ETCD Backup Storage Path. Refer to Point 2 for more information.
$ sudo cat /etc/pf9/host_id.conf[hostagent]host_id = a97d96ae-a311-44fe-8df6-6342f1158bd3 # etcdctl snapshot restore /path/to/snapshshot_file --data-dir /var/opt/pf9/kube/etcd/data --initial-advertise-peer-urls="https://<NODE_IP>:2380" --initial-cluster="<NODE_UUID>=https://<NODE_IP>:2380" --name="<NODE_UUID>" # etcdctl snapshot restore /etcd-backup/etcd_db_snapshot.db --data-dir /var/opt/pf9/kube/etcd/data --initial-advertise-peer-urls="https://10.128.233.61:2380" --initial-cluster="a97d96ae-a311-44fe-8df6-6342f1158bd3=https://10.128.233.61:2380" --name="a97d96ae-a311-44fe-8df6-6342f1158bd3"{"level":"info","ts":1629898238.3696785,"caller":"snapshot/v3_snapshot.go:296","msg":"restoring snapshot","path":"/etcd-backup/etcd_db_snapshot.db","wal-dir":"/var/opt/pf9/kube/etcd/data/member/wal","data-dir":"/var/opt/pf9/kube/etcd/data","snap-dir":"/var/opt/pf9/kube/etcd/data/member/snap"}{"level":"info","ts":1629898238.6159854,"caller":"mvcc/kvstore.go:380","msg":"restored last compact revision","meta-bucket-name":"meta","meta-bucket-name-key":"finishedCompactRev","restored-compact-revision":142938}{"level":"info","ts":1629898238.6445835,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"c3d70c9768f5bc3","local-member-id":"0","added-peer-id":"2e9b087b3a2c5d50","added-peer-peer-urls":["https://10.128.233.61:2380"]}{"level":"info","ts":1629898238.654395,"caller":"snapshot/v3_snapshot.go:309","msg":"restored snapshot","path":"/etcd-backup/etcd_db_snapshot.db","wal-dir":"/var/opt/pf9/kube/etcd/data/member/wal","data-dir":"/var/opt/pf9/kube/etcd/data","snap-dir":"/var/opt/pf9/kube/etcd/data/member/snap"}- Start PMK Stack on the same node.
$ sudo /opt/pf9/nodelet/nodeletd phases start- Once the PMK stack is up, check the member list for ETCD. There should just be one member in the cluster.
# etcdctl member list# etcdctl endpoint health # etcdctl member list2e9b087b3a2c5d50, started, a97d96ae-a311-44fe-8df6-6342f1158bd3, https://10.128.233.61:2380, https://10.128.233.61:4001, false# etcdctl endpoint health127.0.0.1:2379 is healthy: successfully committed proposal: took = 4.309724ms- Detach the other master nodes from the cluster. Token can be generated by referring to Keystone Identity API.
# curl --request POST \ --url https://undefined/qbert/v4/{project_uuid}/clusters/{uuid}/detach \ --header "X-Auth-Token: {X-Auth-Token}" \ --header "Content-Type: application/json" \ --data '[ { "uuid": "{string}", "isMaster": "1" }]' # curl --request POST --url https://cse-k8s.platform9.net/qbert/v4/abcdefghdc7d43f7bbbfaca1afe4bxyz/clusters/xx36195d-ra35-4ee8-82f9-7a7957702md5/detach --header "Content-Type: application/json" --header "X-Auth-Token: $TOKEN" --data '[ { "uuid": "1z45b08f-141e-4995-a236-81ce99d0krto", "isMaster": "1" }]'- In case, the master nodes are hard offline/unreachable, proceed to deauthorize the nodes as well.
# curl -X DELETE -H "X-Auth-Token: $TOKEN" https://<DU_FQDN>/resmgr/v1/hosts/<NODE_UUID>/roles/pf9-kube # curl -X DELETE -H "X-Auth-Token: $TOKEN" https://cse-k8s.platform9.net/resmgr/v1/hosts/1z45b08f-141e-4995-a236-81ce99d0krto/roles/pf9-kube- From Kubectl perspective, the detached master nodes will be seen to be in "NotReady" state. Delete these nodes from the cluster.
# kubectl delete nodes <node-id># kubectl get nodesNAME STATUS ROLES AGE VERSION10.128.233.13 Ready worker 23h v1.20.510.128.233.25 NotReady master 22h v1.20.510.128.233.55 NotReady master 23h v1.20.510.128.233.61 Ready master 23h v1.20.5# kubectl delete nodes 10.128.233.25node "10.128.233.25" deleted# kubectl delete nodes 10.128.233.55node "10.128.233.55" deleted- Then start the pf9-hostagent service on the active master node. This will take care of starting the pf9-nodeletd service.
$ sudo systemctl start pf9-hostagent- At this point, the cluster should be back up and running with a single master node. Verify the same.
- Scale back up the detached Master nodes from the Platform9 UI. You can perform this action by selecting the cluster in "Infrastructure" tab as shown in below image.
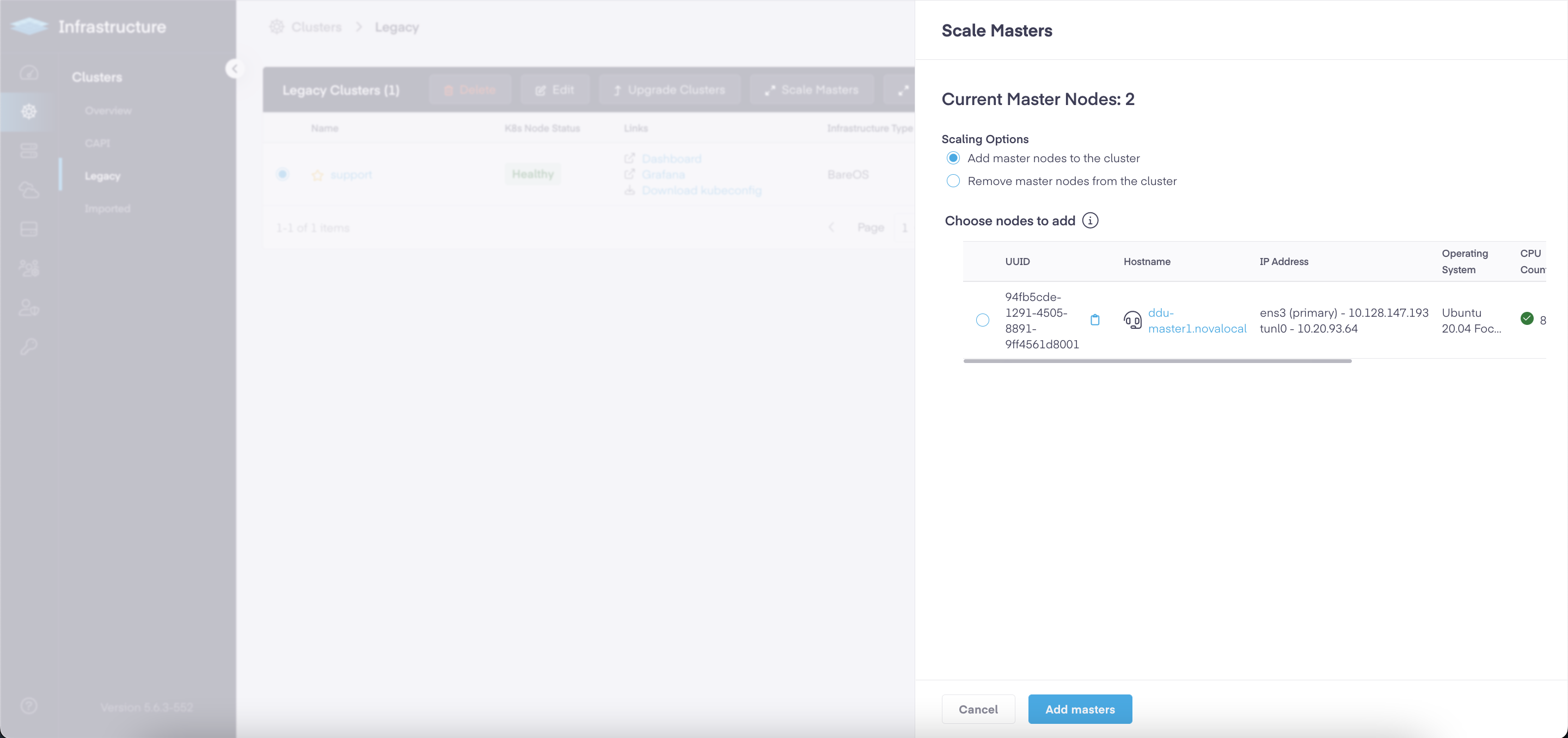
Once the nodes are scaled back up, they should have PMK stack running on them which will ensure ETCD members will sync amongst each other.
# etcdctl member list2e9b087b3a2c5d50, started, a97d96ae-a311-44fe-8df6-6342f1158bd3, https://10.128.233.61:2380, https://10.128.233.61:4001, falsecae96b9604157b3e, started, 9b7a42d2-f5c9-4df2-840f-e84bd8a721e1, https://10.128.233.25:2380, https://10.128.233.25:4001, falsef4e49ab767b773e3, started, 7433a70f-c0fe-4697-a64e-f28480cfe389, https://10.128.233.55:2380, https://10.128.233.55:4001, falseIn case, the other master nodes were deauthorized as well, then new nodes will need to be authorized first before they can be attached. Reference: Authorize-node