Master Node Fails to Attach to an Existing Cluster and UI Shows "Quorum Achieved with a tolerance 1"
Problem
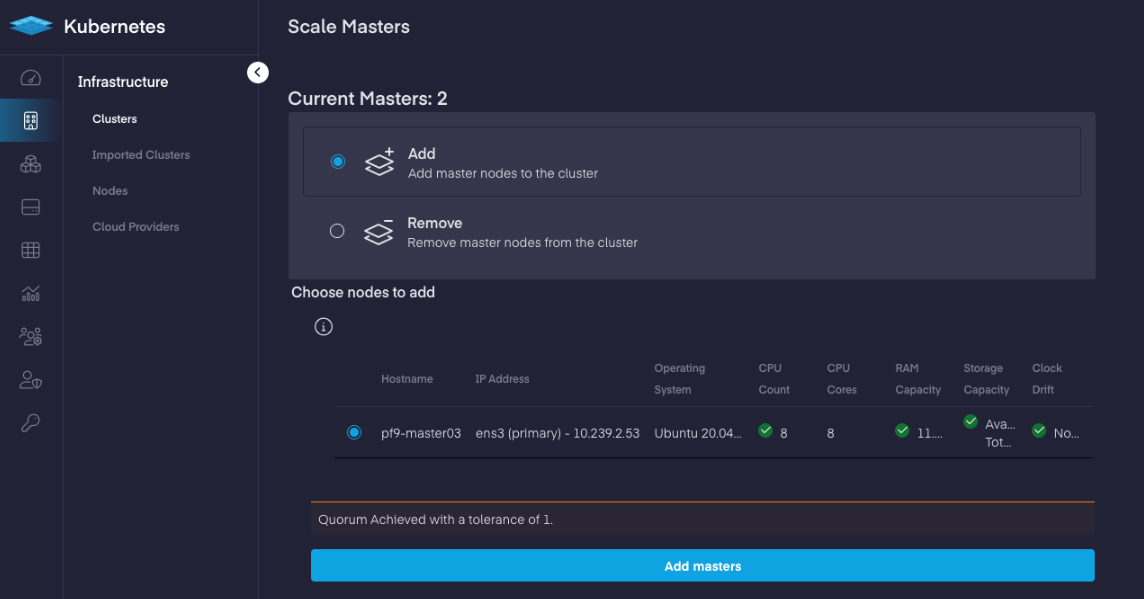
Master node gets failed to attach to an existing cluster. While adding a new master node to a cluster we see "Quorum Achieved with a tolerance 1" message warning as shown below screenshot.
Environment
- Platform9 Managed Kubernetes - v5.6.0 and Higher
Cluster has two master nodes attached already and third master node needs to be attached.
Cause
ETCD member cluster has older member data in database, which doesn't allow new master member to get attached to the cluster. Etcd logs shows below error "failed to reach the peer"
{"log":"{\"level\":\"warn\",\"ts\":\"2023-02 17T03:53:28.271Z\",\"caller\":\"etcdserver/cluster_util.go:315\",\"msg\":\"failed to reach the peer URL\",\"address\":\"https://<IP>:2380/version\",\"remote-member-id\":\"<member-id>\",\"error\":\"Get https://<IP>:2380/version: dial tcp <IP>:2380: i/o timeout\"}\n","stream":"stderr","time":"2023-02-17T03:53:28.27169764Z"}{"log":"{\"level\":\"warn\",\"ts\":\"2023-02-17T03:53:28.271Z\",\"caller\":\"etcdserver/cluster_util.go:168\",\"msg\":\"failed to get version\",\"remote-member-id\":\"<member-id>\",\"error\":\"Get https://<IP>:2380/version: dial tcp <IP>:2380: i/o timeout\"}\n","stream":"stderr","time":"2023-02-17T03:53:28.271755901Z"}{"log":"{\"level\":\"warn\",\"ts\":\"2023-02-17T03:53:28.558Z\",\"caller\":\"rafthttp/peer.go:267\",\"msg\":\"dropped internal Raft message since sending buffer is full (overloaded network)\",\"message-type\":\"MsgHeartbeat\",\"local-member-id\":\"<Local-member-id>\",\"from\":\"<Local-member-id>\",\"remote-peer-id\":\"<member-id>\",\"remote-peer-active\":false}\n","stream":"stderr","time":"2023-02-17T03:53:28.55946179Z"}Resolution
Please follow below steps on Healthy master nodes:
- Check if etcd member endpoint list has older member details present in it, by running endpoint status command on etcd container as shown below
# sudo /opt/pf9/pf9-kube/bin/nerdctl -n k8s.io ps# sudo /opt/pf9/pf9-kube/bin/nerdctl -n k8s.io exec -it etcd -- etcdctl --cacert=/certs/etcd/peer/ca.crt --cert=/certs/etcd/client/request.crt --key=/certs/etcd/client/request.key endpoint status --cluster -w=table- If older entry is present, then run below command to remove stale entry from etcd database.
# sudo /opt/pf9/pf9-kube/bin/nerdctl -n k8s.io exec -it etcd -- etcdctl --cacert=/certs/etcd/peer/ca.crt --cert=/certs/etcd/client/request.crt --key=/certs/etcd/client/request.key member remove <ID>- Retry attaching a master node to existing cluster. Now, it should successfully get attached to master node.
Was this page helpful?