Scale Cluster
You can manually scale up or down a Platform9 Managed Kubernetes cluster regardless of whether the clusters are deployed on-premises or in a public cloud. For clusters created on AWS, you can also enable auto-scaling for worker nodes, so the clusters are scaled up or down automatically based on workload.
You must be a Platform9 administrator to perform this operation.
Scaling On-Premises Clusters
Scaling On-Premises Cluster Master Nodes
Follow the steps given below to scale the master nodes for an on-premises BareOS cluster:
1) Navigate to Infrastructure > Clusters.
2) Select the BareOS cluster that you wish to scale.
3) ClickScale Masters action from the action bar above the clusters table.

4) Change the current number of master nodes to your desired number. If the number of workers you specified is smaller than the current number of workers, your cluster will be scaled down to that number. If the number you specified is greater than the current number, your cluster will be scaled up.
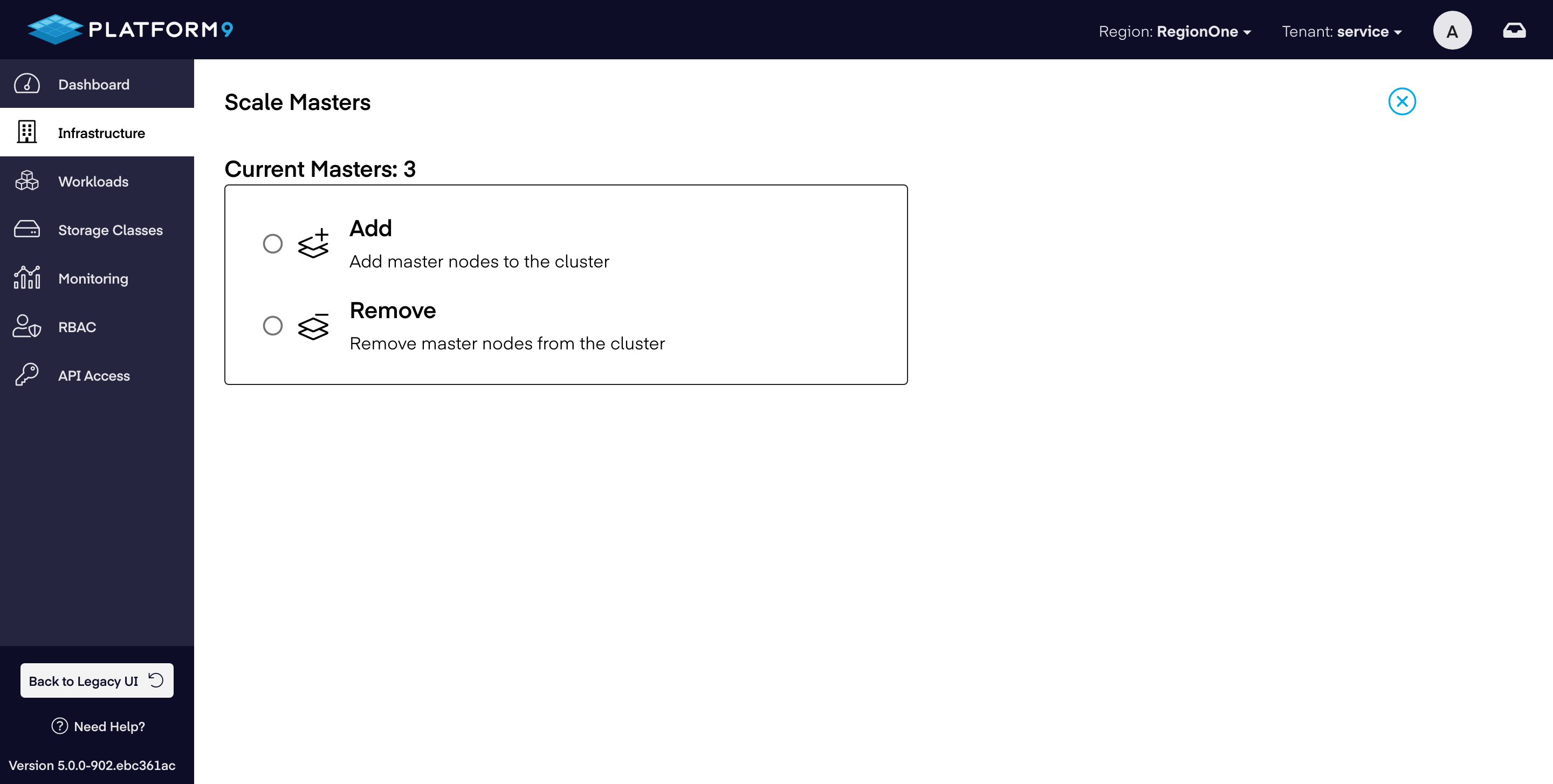
5) Click Scale Cluster.
The changes related to scaling of the cluster are saved.
Scaling On-Premises Cluster Worker Nodes
Follow the steps given below to scale the master nodes for an on-premises BareOS cluster:
- Navigate to Infrastructure > Cluster.
- Select the BareOS cluster that you wish to scale.
- Click
Scale Workersaction from the action bar above the clusters table. - Change the current number of master nodes to your desired number. If the number of workers you specified is smaller than the current number of workers, your cluster will be scaled down to that number. If the number you specified is greater than the current number, your cluster will be scaled up.
- Click Scale Cluster.
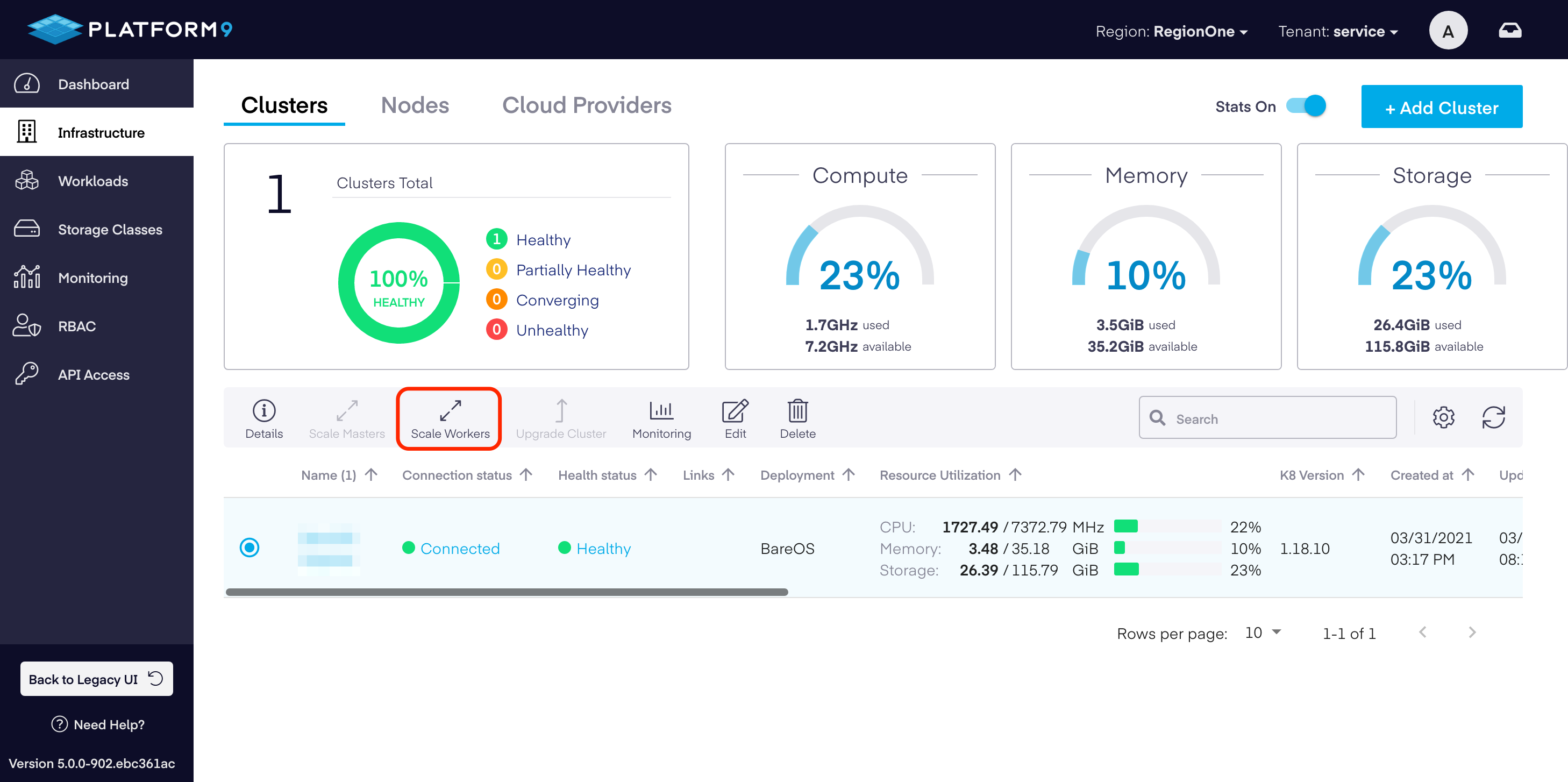
The changes related to scaling of the cluster are saved.
Scaling AWS
Scaling of master nodes for an AWS cluster is not supported in PMK today. If you wish to scale master nodes of an existing AWS cluster, please ask for help on Platform9 slack / forum or contact support.
Scaling AWS Worker Nodes
Follow the steps given below to scale the worker nodes for an AWS cluster:
- Navigate to Infrastructure > Clusters.
- Select the AWS cluster that you wish to scale.
- Click
Scale Workersaction from the action bar above the clusters table. - If auto-scaling is not enabled for the cluster, change the current number of worker nodes to your desired number. If the number of workers you specified is smaller than the current number of workers, your cluster will be scaled down to that number. If the number you specified is greater than the current number, your cluster will be scaled up.
- If auto-scale is enabled on the cluster, you will see two fields. Minimum__Number of Worker Nodes denotes the minimum number of worker nodes to which the cluster can auto-scale down to, and the Maximum Number of Worker Nodes denotes the maximum number of worker nodes to which the cluster can auto-scale up to.
- Enter new values for minimum and maximum number of worker nodes to change the auto-scaling config for the cluster.
- Click Scale Cluster.
The changes related to scaling of the cluster are saved.
Autoscaling AWS Clusters - Scaling Criteria And Timing
For clusters created with AWS, if you have enabled horizontal auto-scaling on the cluster, you can change the minimum number of nodes and the maximum number of nodes available for scaling the cluster up or down automatically. The Kubernetes cluster autoscaler behind the scene handles scaling up and down of the cluster by updating the worker autoscaling group’s desired size, based on certain conditions.
For more information on Kubernetes cluster autoscaler, refer to the following Kubernetes documentation on cluster autoscaler: https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#what-is-cluster-autoscaler
Scale Up Criteria And Timing
Kubernetes cluster autoscaler increases the size of the cluster when:
- There are pods that failed to schedule on any of the current nodes due to insufficient resources (CPU, memory etc).
- Adding a node similar to the nodes currently present in the cluster would help.
By default, Kubernetes configures cluster autoscaler to check for any unschedulable pods every 10 seconds (configurable by –scan-interval API server flag). A pod is unschedulable when the Kubernetes scheduler is unable to find a node that can accommodate the pod (for example a pod can request more CPU that is available on any of the cluster nodes.) Unschedulable pods are recognized by their PodCondition. Whenever a Kubernetes scheduler fails to find a place to run a pod, it sets “schedulable” PodCondition to false and reason to “unschedulable”. If there are any items in the unschedulable pods list, Cluster Autoscaler tries to find a new place to run them by updating the worker autoscaling group’s desired size.
This update to the AWS autoscaling group will trigger deployment of new nodes to make the current number of nodes match the new desired number.
It may take some time before the created nodes appear in Kubernetes. The Kubernetes cluster autoscaler expects requested nodes to appear within 15 minutes (configured by –max-node-provision-time API server flag.)
Scale Down Criteria And Timing
Every 10 seconds (configurable by –scan-interval API server flag), if no scale-up is needed, Cluster Autoscaler checks which nodes are not needed. A node is considered for removal when all of the following conditions hold true:
- The sum of CPU and Memory requests of all pods running on this node is smaller than 50% of the node’s allocatable. Utilization threshold can be configured using –scale-down-utilization-threshold flag.
- All pods running on the node (except these that run on all nodes by default, like manifest-run pods or pods created by daemonsets) can be moved to other nodes. See What types of pods can prevent CA from removing a node? section for more details on what pods don’t fulfill this condition, even if there is space for them elsewhere. While checking this condition, the new locations of all movable pods are memorized. With that, Cluster Autoscaler knows where each pod can be moved, and which nodes depend on which other nodes in terms of pod migration. Of course, it may happen that eventually the scheduler will place the pods somewhere else.( All pods should be migrated elsewhere. Cluster Autoscaler does this by evicting them and tainting the node, so they aren’t scheduled there again.)
- It doesn’t have scale-down disabled annotation (see https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#how-can-i-prevent-cluster-autoscaler-from-scaling-down-a-particular-node)
If a worker node is not needed (per the above criteria) for more than 10 minutes (default, can be customized), it will be terminated by scaling the cluster down. When a node is terminated by the autoscaler, all pods running on the cluster are evicted. The autoscaler also taints the node so the pods aren’t scheduled there again. All pods then get migrated to other nodes and then the node gets removed.
Cluster is not scaled down if current number of workers is equal to minNumWorkers.