# Flannel Crashing on Worker Nodes After Upgrading AWS Clusters to v1.22
## Problem
Workloads on a flannel-based AWS cluster will start failing after upgrading a cluster to v1.22. The flannel container fails to create network configuration and the following logs are observed in the container logs
{% tabs %}
{% tab title="Javascript" %}
```javascript
I0202 20:33:07.185453 1 main.go:254] Created subnet manager: Etcd Local Manager with Previous Subnet: None
I0202 20:33:07.185459 1 main.go:257] Installing signal handlers
E0202 20:33:08.186083 1 main.go:388] Couldn't fetch network config: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 10.254.8.210:2379: i/o timeout timed out
```
{% endtab %}
{% endtabs %}
## Environment
* Platform9 Managed Kubernetes - v5.6 and Higher
* Kubernetes - v1.22
* Flannel CNI
* AWS
## Cause
The *flannel* containers on worker nodes fail to communicate with the *etcd* cluster due to a change in client communication port from 4001 to 2379 since the latter is secure.
## Resolution
{% hint style="info" %}
**Info**
We recommend performing the following steps for each cluster before upgrading the clusters to v1.22. The following steps also work to resolve the issue if the cluster has already been upgraded to v1.22.
{% endhint %}
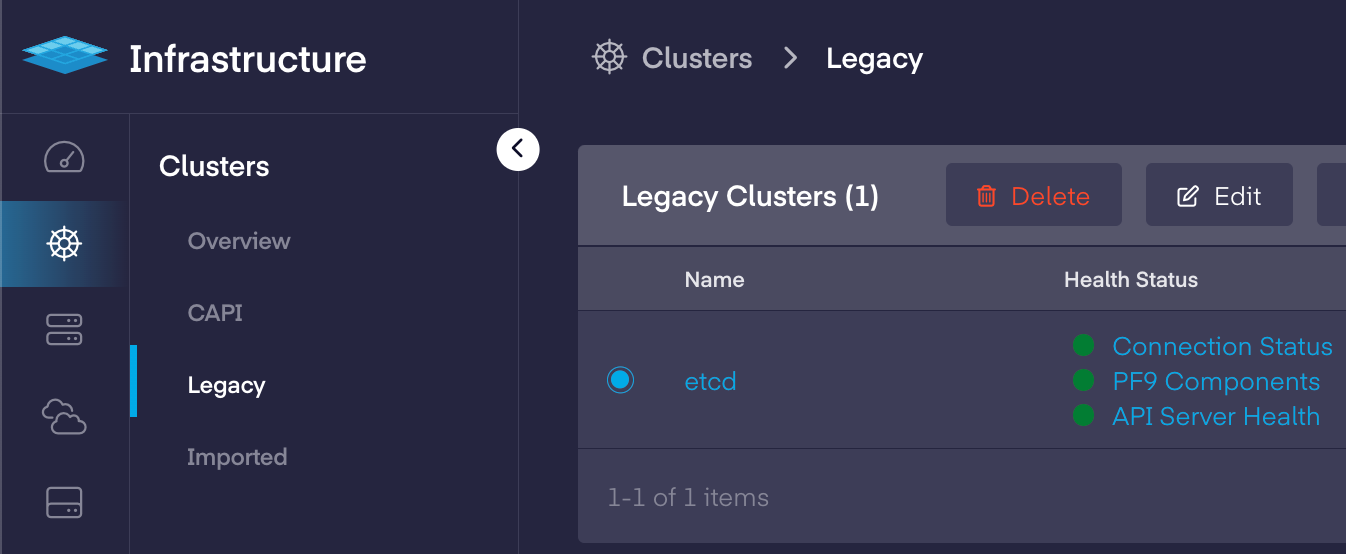
1. Navigate to the "*Clusters"* tab under the "*Infrastructure"* section to select the *cluster* and click on the "*Edit"* button.
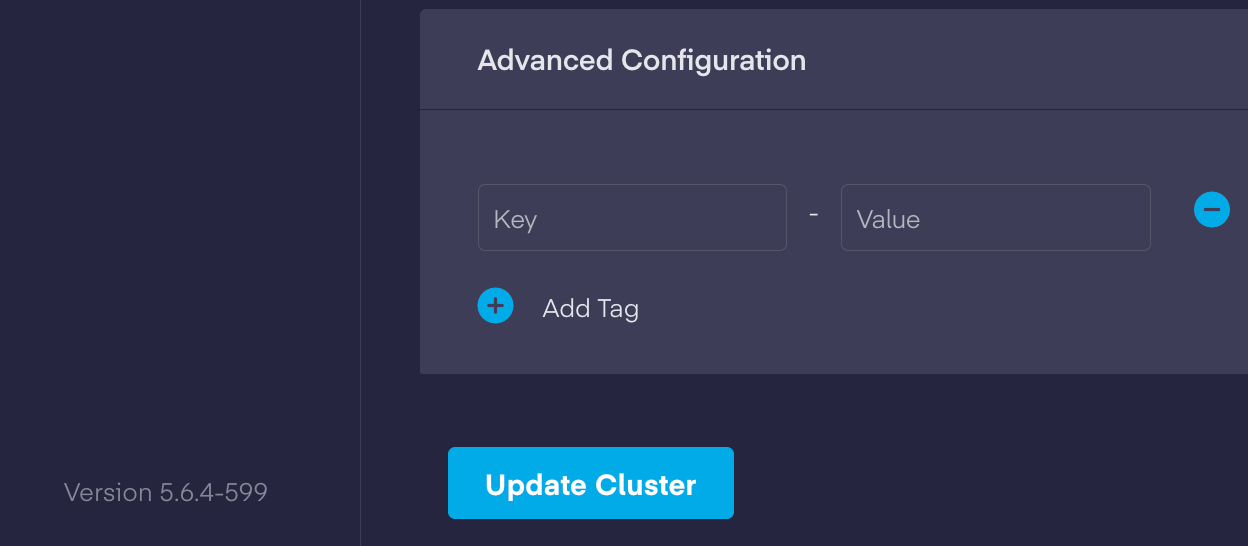
2. Without making any changes in the "*Edit*" section, proceed to scroll down to the bottom and click on "*Update Cluster*" button.